Spring DB 접근 기술
- JDBC 는 SQL 로 서버랑 DB 연결하는 기술이다.
- JdbcTemplate 을 통해 SQL 를 편리하게 날릴 수 있다.
- JPA 기술이 등록, 수정, 삭제 쿼리를 만들어서 날려준다.
순수 JDBC
-
build.gradle에서 jdbc, h2 DB 관련 라이브러리를 추가한다.implementation 'org.springframework.boot:spring-boot-starter-jdbc' runtimeOnly 'com.h2database:h2' -
application.properties에서 스프링 부트 DB 연결 설정을 추가한다.spring.datasource.url=jdbc:h2:tcp://localhost/~/test spring.datasource.driver-class-name=org.h2.Driver spring.datasource.username=sa
Jdbc Repository 구현 후 스프링 설정 변경
@Configuration
public class SpringConfig {
private final DataSource dataSource;
public SpringConfig(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository());
}
@Bean
public MemberRepository memberRepository() {
// return new MemoryMemberRepository();
return new JdbcMemberRepository(dataSource);
}
}- 기존에 사용하던
MemoryMemberRepository를JdbcMemberRepository로 변경한다. DataSource는 DB Connection 을 획득할 때 사용하는 객체다.- 스프링 부트는 DB Connection 정보를 바탕으로
DataSource를 생성하고 스프링 빈으로 만들어 DI 를 받을 수 있다. MemberService는 인터페이스인MemberRepository를 의존하고 있기 때문에MemberRepository의 구현체를 모두 참조할 수 있다.- 변경된
@Configuration을 바탕으로 스프링 컨테이너 내부에서 DI 를memberRepository로 변경할 수 있다. - OCP(Open-Closed Principle, 개방-폐쇄 원칙)
- 확장에는 열려있고, 수정, 변경에는 닫혀있다.
- 객체지향 프로그래밍의 다형성을 통해 OCP 원칙을 지켜낼 수 있다.
- 스프링의 DI 를 사용하여 기존 코드를 전혀 손대지 않고, 설정만으로 구현 클래스를 변경할 수 있다.
스프링 통합 테스트
- 테스트 클래스 단위에
@SpringBootTest를 추가하여 스프링 컨테이너와 테스트를 함께 실행한다. - 테스트 클래스 단위에
@Transactional을 추가하면, 테스트 시작 전에 Transaction 을 시작하고, 테스트 완료 후에 항상 롤백한다.
스프링 JdbcTemplate
- 순수 JDBC 에서 중복되는 코드들을 제거하여 간단하게 DB 에 접근할 수 있는 코드를 작성하는데 도움을 주는 template 이다.
public JdbcTemplateMemberRepository(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}- 스프링 컨테이너의 DI 를 통해
JdbcTemplate에DataSource를 주입하여 사용한다.
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(jdbcTemplate);
jdbcInsert.withTableName("member").usingGeneratedKeyColumns("id");
Map<String, Object> parameters = new HashMap<>();
parameters.put("name", member.getName());
Number key = jdbcInsert.executeAndReturnKey(new MapSqlParameterSource(parameters));
member.setId(key.longValue());SimpleJdbcInsert를 통해INSERT쿼리문과 함께 자동생성되는 id 값을 반환 받을 수 있다.
JPA
JPA 를 통해 기본적인 SQL 을 JPA 가 만들어 실행하고, SQL 중심 설계에서 객체 중심 설계로 개발을 진행할 수 있다. 즉, JPA 를 통해 개발 생산성을 크게 높일 수 있다. JPA 는 인터페이스이며 구현체로 Hibernate 를 많이 사용한다. JPA 는 ORM 기술로서 Object Relational Mapping 의 약자이다. 즉, 객체와 RDB 를 매핑해주는 기술이다.
build.gradle 에 dependencies 추가
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
// implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.h2database:h2'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}spring-boot-starter-data-jpa 내부에 jdbc 관련 라이브러리를 포함하기 때문에 jdbc 는 제거해도 된다.
application.properties 에 설정 추가
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=noneshow-sql설정을 통해 JPA 가 생성하는 SQL 을 출력한다.ddl-autoJPA 는 테이블을 자동으로 생성하는 기능을 제공하는데,none을 설정해주면 해당 기능을 사용하지 않게된다.create설정 시 엔티티 정보를 바탕으로 테이블도 직접 생성해준다.
JPA 엔티티 매핑
package hello.hellospring.domain;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}@Entity 를 통해 객체가 엔티티라는 것을 명시한다.
@Id 를 통해 해당 필드가 DB 의 Id 값이라고 명시해준다.
@GeneratedValue(strategy = GenerationType.IDENTITY) 를 통해 AUTO_INCREMENT 되는 값이라는 것을 명시해준다.
JPA 회원 Repository
package hello.hellospring.repository;
import hello.hellospring.domain.Member;
import javax.persistence.EntityManager;
import java.util.List;
import java.util.Optional;
public class JpaMemberRepository implements MemberRepository {
private final EntityManager em;
public JpaMemberRepository(EntityManager em) {
this.em = em;
}
public Member save(Member member) {
em.persist(member);
return member;
}
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}
public List<Member> findAll() {
return em.createQuery("select m from Member m", Member.class)
.getResultList();
}
public Optional<Member> findByName(String name) {
List<Member> result = em.createQuery("select m from Member m where m.name = :name", Member.class)
.setParameter("name", name)
.getResultList();
return result.stream().findAny();
}
}Spring DI 를 통해 EntityManager 를 주입해준다. 주입된 em 을 통해 모든 기능을 구현할 수 있다.
JPA 는 조회 로직이 Id 값으로 찾는 기능만 제공하기 때문에, findByName(String name) 와 같은 로직을 수행하기 위해선 JPQL 이라는 객체 지향 쿼리를 통해 JPA 를 사용할 수 있다.
Spring Data 를 사용하면 JPQL 도 사용하지 않을 수 있다.
Service 계층에 Transaction 추가
import org.springframework.transaction.annotation.Transactional
@Transactional
public class MemberService {}모든 데이터 변경이 Transaction 안에서 실행되어야 하기 때문에 @Transactional 애너테이션이 필요하다.
JPA 를 사용하도록 스프링 설정 변경
package hello.hellospring;
import hello.hellospring.repository.*;
import hello.hellospring.service.MemberService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.sql.DataSource;
@Configuration
public class SpringConfig {
private final DataSource dataSource;
private final EntityManager em;
public SpringConfig(DataSource dataSource, EntityManager em) {
this.dataSource = dataSource;
this.em = em;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository());
}
@Bean
public MemberRepository memberRepository() {
// return new MemoryMemberRepository();
// return new JdbcMemberRepository(dataSource);
// return new JdbcTemplateMemberRepository(dataSource);
return new JpaMemberRepository(em);
}
}EntityManager 를 DI 받기 위해서 SpringConfig 클래스에서 추가적인 설정을 해주어야 한다.
Spring Data JPA
Spring Boot 와 JPA 만 사용해도 개발 생산성이 많이 증가하며, 개발해야 할 코드도 확연히 줄어든다. Spring Data JPA 를 사용하면, Repository 구현 클래스 없이 인터페이스 만으로 개발을 완료할 수 있다. Spring Data JPA 는 JPA 를 편리하게 해주는 도구일 뿐이기 때문에 JPA 를 먼저 학습해야한다.
스프링 데이터 JPA 회원 Repository
package hello.hellospring.repository;
import hello.hellospring.domain.Member;
import java.util.Optional;
import org.springframework.data.jpa.repository.JpaRepository;
public interface SpringDataJpaMemberRepository extends JpaRepository<Member, Long>, MemberRepository {
@Override
Optional<Member> findByName(String name);
}JpaRepository 와 사용할 Repository 인 MemberRepository 를 상속받은 새로운 인터페이스를 구현한 후 기존에 JPQL 로 구현한 메서드를 Override 해주면 끝이다.
Spring Data 가 해당 인터페이스를 찾아 메서드를 알아서 만들어 준다.
스프링 데이터 JPA 회원 Repository 를 사용하도록 설정 변경
package hello.hellospring;
import hello.hellospring.repository.MemberRepository;
import hello.hellospring.service.MemberService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SpringConfig {
private final MemberRepository memberRepository;
public SpringConfig(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository);
}
}해당 설정을 통해 Spring 이 알아서 SpringDataJpaMemberRepository 를 찾아 DI 해준다.
주의할 점은, SpringDataJpaMemberRepository 외에 다른 구현체에 @Repository 애너테이션이 추가되어 있으면, Bean 이 2가지가 등록되어 있기 때문에 컴파일 에러가 발생한다.
스프링 데이터 JPA 제공 기능
스프링 데이터 JPA 는 인터페이스를 통해 기본적인 CRUD 를 제공한다. 또한, findByName() findByEmail() 처럼 메서드 이름 만으로도 JPQL 을 자동으로 생성하여 조회 기능을 제공한다.
추가적으로, PagingAndSortingRepository 를 통해 페이징 기능도 자동으로 제공한다.
실무에서는 JPA 와 스프링 데이터 JPA 를 기본으로 사용하고, 복잡한 동적 쿼리는 Querydsl 이라는 라이브러리를 사용한다. Querydsl 을 사용하면 자바 코드로 쿼리도 안전하게 작성할 수 있고, 동적 쿼리도 편리하게 작성할 수 있다. 이 조합으로 해결하기 어려운 쿼리는 JPA 가 제공하는 네이티브 쿼리를 사용하거나, JdbcTemplate 을 사용할 수 있다.
SQL 중심적인 개발의 문제점
JPA 와 모던 자바 데이터 저장 기술
현대 애플리케이션은 객체 지향 언어를 주로 사용하고, 데이터베이스는 관계형 DB 를 사용한다. 즉, 지금 시대는 객체를 관계형 DB 에 저장해서 사용하고 있다.
SQL 중심적인 개발의 문제점
무한 반복되는 지루한 CRUD 코드를 작성해야 하며, 객체 속성이 추가될 때 마다 아래와 같이 SQL 쿼리문이 자주 변경된다.
public class Member {
private String memberId;
private String name;
private String tel;
}INSERT INTO MEMBER(MEMBER_ID, NAME, TEL) VALUES
SELECT MEMBER_ID, NAME, TEL FROM MEMBER M
UPDATE MEMBER SET ... TEL = ?애초에 객체 지향과 관계형 데이터베이스의 사상은 완전히 다르다. 관계형 데이터베이스는 데이터를 정규화해서 보관하는 것이 목표인 반면, 객체 지향 프로그래밍은 속성과 기능을 잘 묶어서 캡슐화하여 사용하는 것이 목표다.
그럼 왜 굳이 SQL?
객체를 영구 보관하는 다양한 저장소가 존재하지만, 그 중에 가장 현실적인 대안이 관계형 데이터베이스였을 뿐이다. 즉, SQL 에 의존적인 개발을 피하기 어렵다.
객체와 관계형 DB 의 차이
1. 상속
2. 연관관계
3. 데이터 타입
4. 데이터 식별 방법
객체와 관계형 DB 에는 위와 같은 차이점들이 있는데, 간단히 상속과 연관관계를 살펴보자. 객체 지향 프로그래밍에는 상속 관계가 존재하지만, 관계형 DB 에는 없다고 볼 수 있다. 연관관계 또한, 객체 지향 프로그래밍에서는 getter 를 통해 연관된 객체를 가져오지만, 관계형 DB 에서는 PK, FK 등으로 연관된 데이터를 가져온다.
상속
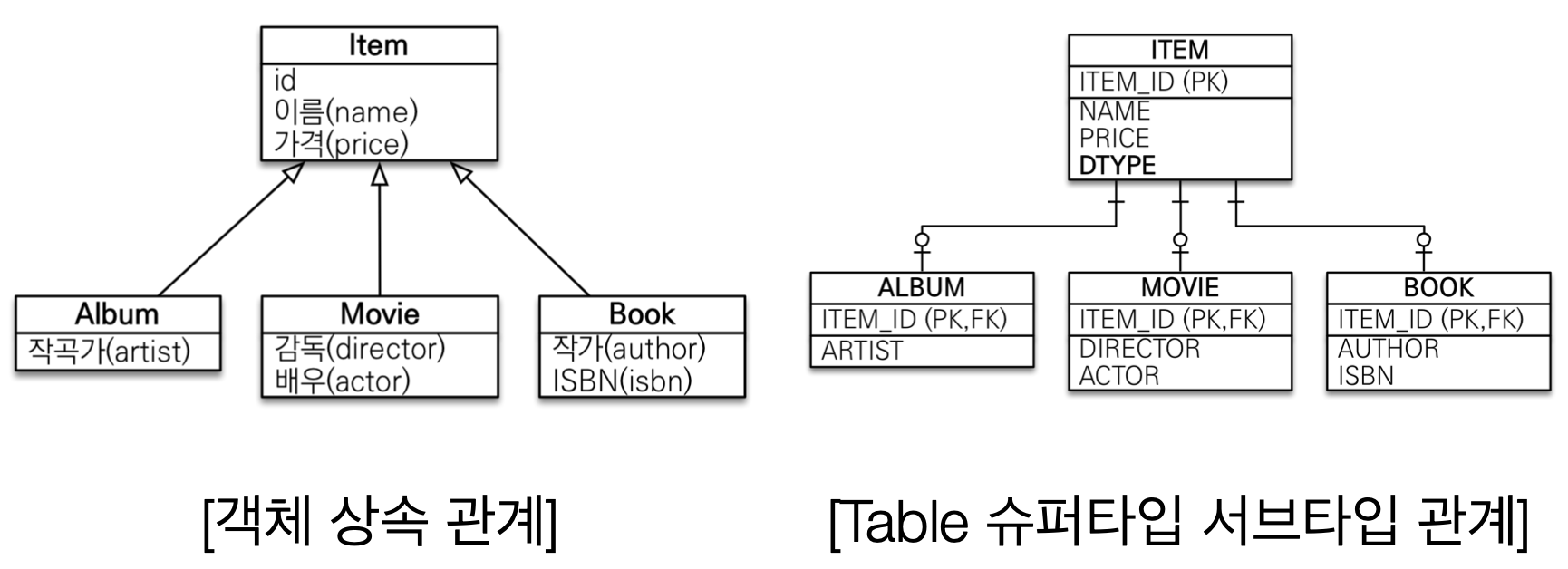 객체의 상속 관계 설계를 위와 같이 만들어냈다고 가정해보자.
위와 같이 설계된 객체를 DB 에 저장하기 위해선 어떻게 해야할까?
객체의 상속 관계와 그나마 유사한 슈퍼타입, 서브타입 모델로 DB 에 저장한다.
테이블을 설계하고 객체를 저장하고 조회하는 과정을 살펴보자.
객체의 상속 관계 설계를 위와 같이 만들어냈다고 가정해보자.
위와 같이 설계된 객체를 DB 에 저장하기 위해선 어떻게 해야할까?
객체의 상속 관계와 그나마 유사한 슈퍼타입, 서브타입 모델로 DB 에 저장한다.
테이블을 설계하고 객체를 저장하고 조회하는 과정을 살펴보자.
Album 객체를 저장하려면?
1. 객체 분해
2. INSERT INTO ITEM …
3. INSERT INTO ALBUM …
여기까지는 괜찮은 것 같다.
Album 객체를 조회하려면?
1. 각각의 테이블에 따른 JOIN SQL 작성…
2. 각각의 객체 생성…
상상만 해도 복잡하다. 그래서 DB 에 저장할 객체에는 상속 관계를 사용하지 않는다.
DB 가 아니라 자바 컬렉션에 저장한다면?
list.add(album);
Album album = list.get(albumId);
// 부모 타입으로 조회 후 다형성 활용도 가능
Item item = list.get(albumId);문득 자바 컬렉션을 사용한다면 훨씬 간편할 것 같다는 생각이 살살 든다.
연관관계
이번엔 OOP 와 RDB 의 연관관계에 어떤 차이점이 있는지 살펴보자.

member.getTeam();객체는 참조를 사용한다. 객체는 단방향 참조기 때문에 Team 으로 Member 를 찾을 수 없다.
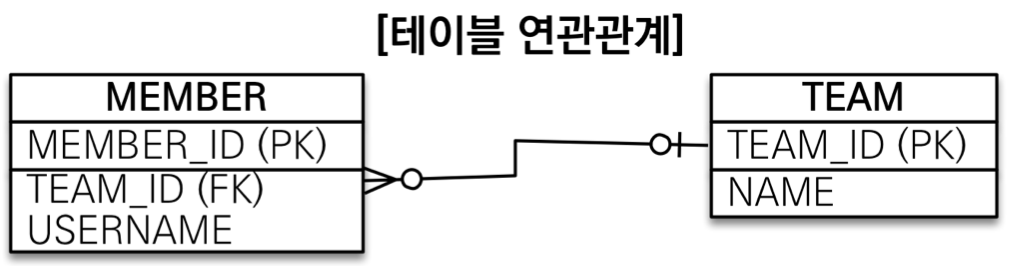
JOIN ON M.TEAM_ID = T.TEAM_ID테이블은 외래 키를 사용한다. 때문에 Team 으로 Member 를 찾을 수 있다.
즉, 테이블은 양방향으로 찾을 수 있다.
객체를 테이블에 맞추어 모델링
앞서 예시로 들었던 객체를 DB 에 저장하려고 할 때, 테이블 설계에 맞춰 객체를 모델링하여 아래와 같이 객체를 저장할 수 있을 것이다.
class Member {
String id;
Long teamId;
String username;
}class Team {
Long id;
String name;
}INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...하지만, Member 내부에 teamId 가 있는 것이 뭔가 객체 지향적이지 않은 것 같다.
객체 지향적으로 모델링을 변경해보자.
객체 지향적인 모델링
class Member {
String id;
Team team;
String username;
Team getTeam() {
return team;
}
}class Team {
Long id;
String name;
}// member.getTeam().getId() 로 TEAM_ID 를 가져옴
INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...모델링을 객체지향적으로 변경하자, SQL 문에서 TEAM_ID 를 요구할 때, member.getTeam().getId() 와 같은 코드가 필요해진다.
여기까진 괜찮은 것 같다.
객체 모델링 조회
하지만 조회를 할 경우에 문제가 발생한다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_IDpublic Member find(String memberId) {
//SQL 실행 ...
Member member = new Member();
//데이터베이스에서 조회한 회원 관련 정보를 모두 입력
Team team = new Team();
//데이터베이스에서 조회한 팀 관련 정보를 모두 입력
//회원과 팀 관계 설정
member.setTeam(team); //
return member;
}JOIN 구문이 포함된 SQL 쿼리를 통해 모든 데이터를 가져와서 각각 객체를 생성하여 관계를 설정해주어야한다. 자바 컬렉션 API 가 그리워지는 순간이다.
객체 모델링, 자바 컬렉션에 관리
list.add(member);
Member member = list.get(memberId);
Team team = member.getTeam();위 처럼 자바 컬렉션 API 를 사용한다면 정말 쉬울텐데…
객체 그래프 탐색
 객체는 자유롭게 객체 그래프를 탐색할 수 있어야 한다.
하지만 처음 실행하는 SQL 에 따라 탐색 범위가 결정된다.
예를 들어 아래와 같은 SQL 을 통해 객체를 가져온다고 가정해보자.
객체는 자유롭게 객체 그래프를 탐색할 수 있어야 한다.
하지만 처음 실행하는 SQL 에 따라 탐색 범위가 결정된다.
예를 들어 아래와 같은 SQL 을 통해 객체를 가져온다고 가정해보자.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID객체 생성 시점에 team 필드만 채워 넣었기 때문에 member.getOrder() 호출 시 null 값이 반환된다.
엔티티 신뢰 문제
위와 같은 상황은 엔티티에 대한 신뢰 문제를 발생할 수 있다. 예를 들어 아래와 같은 코드가 있다고 가정해보자.
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); //???
member.getOrder().getDelivery(); // ???
}
}다른 팀원 누군가가 개발한 memberDAO.find() 를 통해 member 를 조회할 경우, memberDAO 내부에서 어떤 쿼리가 실행되었고, 어떤 데이터를 조립하였는지 확인하지 않는다면, 반환된 엔티티를 신뢰할 수 없다.
모든 객체를 미리 로딩할 수는 없을까?
//Member만 조회
memberDAO.getMember();
//Member와 Team 조회
memberDAO.getMemberWithTeam();
//Member,Order,Delivery 조회
memberDAO.getMemberWithOrderWithDelivery();상황에 따라 동일한 회원 조회 메서드를 여러벌 생성할 수 밖에 없다.
계층형 아키텍처에서 진정한 의미의 계층 분할이 어렵다.
Layered Architecture 에서는 그 다음 계층에서 신뢰하고 사용해야 한다.
물리적으로는 계층이 service 와 dao 로 나뉘어져 있지만, 논리적으론 어느정도 연결되어 있다. 즉, dependency 가 좋지 않다.
DB 조회와 자바 컬렉션 조회 비교하기
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; //다르다.
class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
//JDBC API, SQL 실행
return new Member(...);
}
}String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 == member2; //같다.객체답게 모델링 할수록 매핑 작업만 늘어난다…
SQL 에 맞춰서 객체를 데이터 전송용으로만 설계를 할 수 밖에 없다. 객체 지향적으로 설계를 할 순 있어도, ROI 가 안 나온다.
객체를 자바 컬렉션에 저장 하듯이 DB 에 저장할 순 없을까?
그래서 등장한 것이 바로 JPA(Java Persistence API) 이다.
JPA 소개
JPA 란?
Java Persistence API 의 약자이며, Java 진영의 ORM 기술 표준이다.
ORM 이 뭐야?
Object-Relational Mapping 의 약자로, 객체는 객체대로 설계하고, 관계형 DB 는 관계형 DB 대로 설계하여 객체와 관계형 DB 중간에서 서로를 매핑해주는 프레임워크이다. 대중적인 언어에는 대부분 ORM 기술이 존재한다.
JPA 는 애플리케이션과 JDBC 사이에서 동작
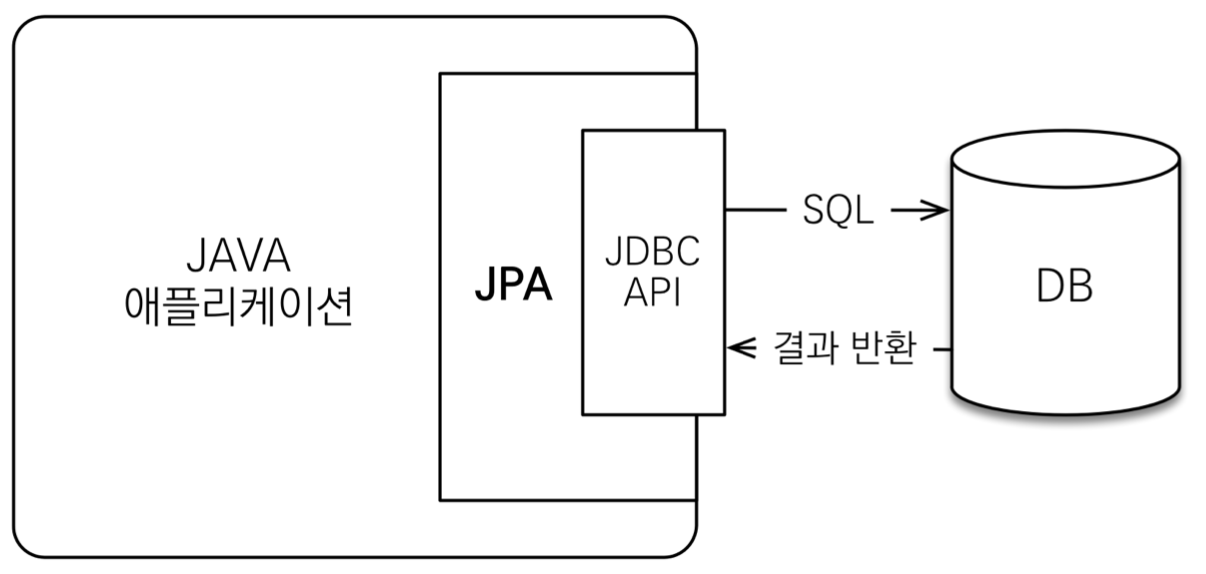 개발자가 아닌 JPA 가 JDBC 를 호출하여 SQL 을 생성하고 DB 와 소통하는 방식으로 동작한다.
개발자가 아닌 JPA 가 JDBC 를 호출하여 SQL 을 생성하고 DB 와 소통하는 방식으로 동작한다.
JPA 동작 - 저장
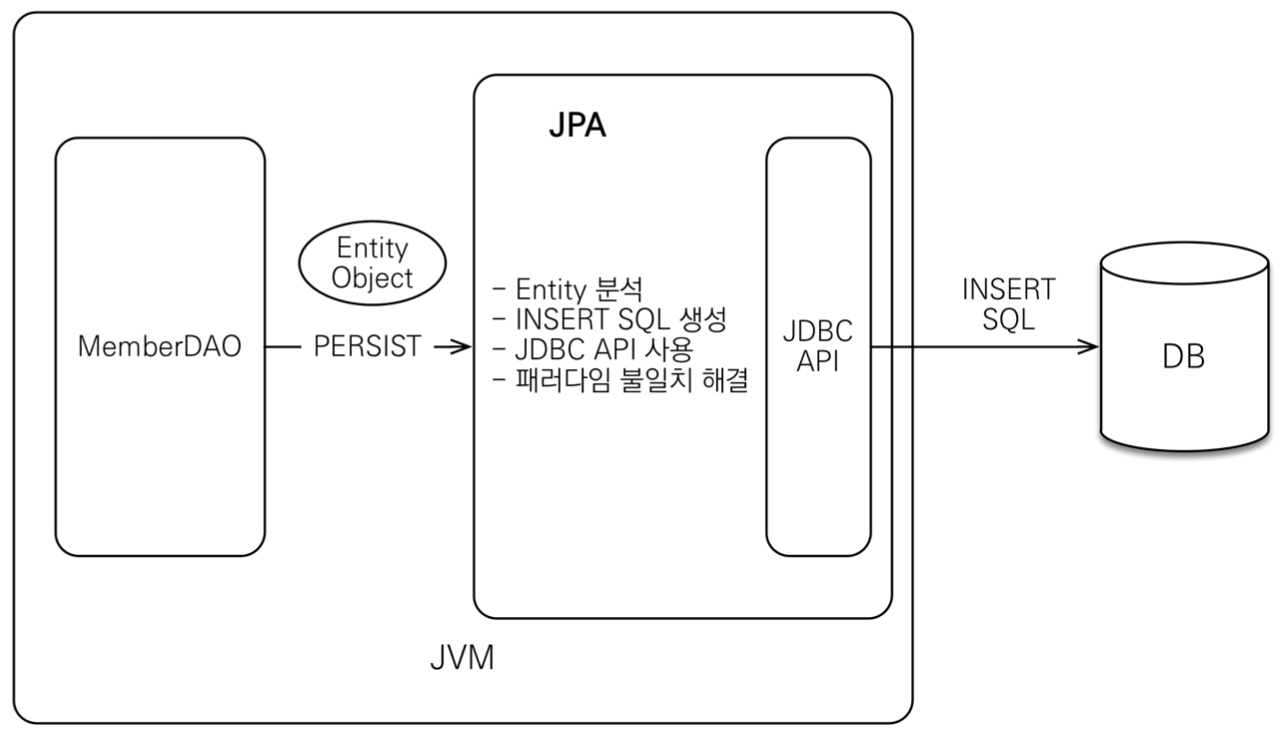
JPA 동작 - 조회
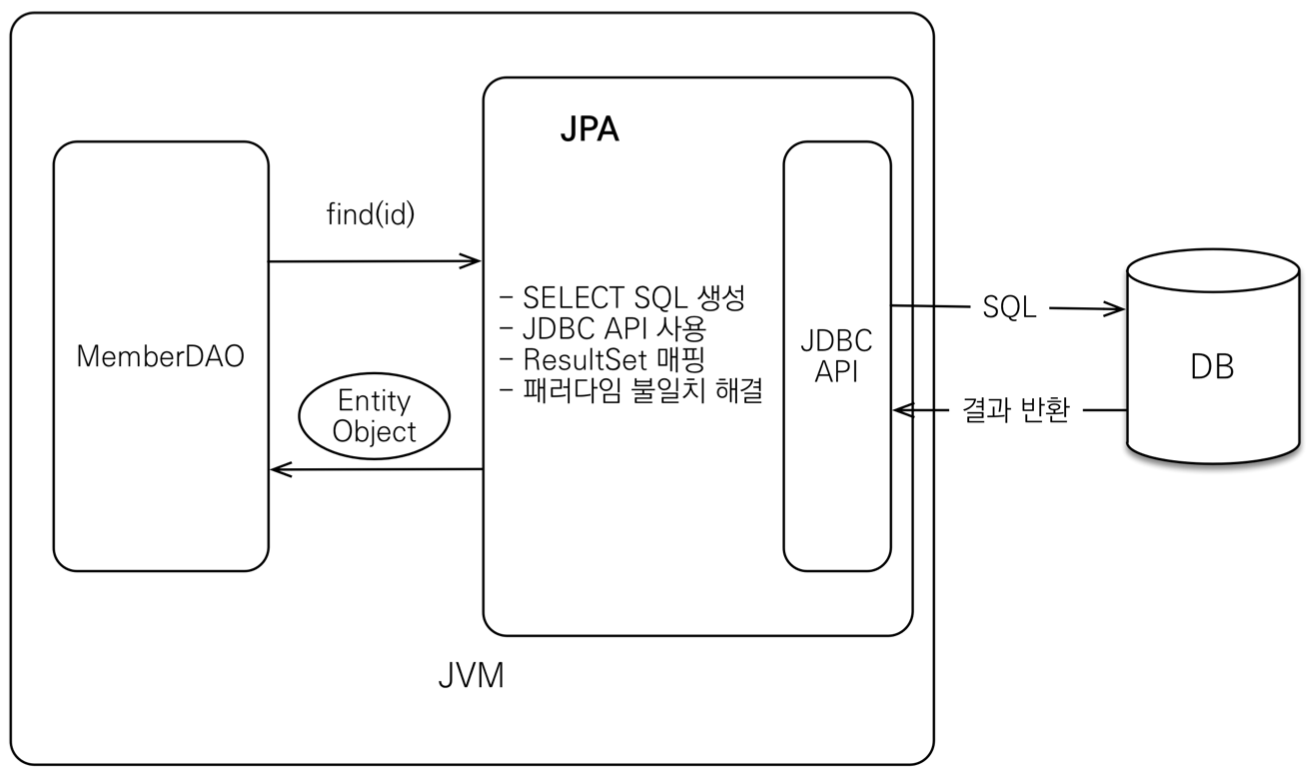
JAP 는 표준 명세
JPA 는 인터페이스의 모음이다. JPA 2.1 표준 명세를 구현한 여러 구현체가 존재하는데, 그중 제일 유명한 3가지 구현체가 하이버네이트, EclipseLink, DataNucleus 이다. 이 중 하이버네이트가 가장 많이 쓰인다.
JPA 를 왜 사용해야 할까?
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준 위와 같이 여러 장점이 있는데 이 중 중요한 요소들을 간단히 살펴보자.
생산성 - JPA 와 CRUD
- 저장 -
jpa.persist(member) - 조회 -
Member member = jpa.find(memberId) - 수정 -
member.setName(”변경할 이름") - 삭제 -
jpa.remove(member)위처럼 SQL 구문 없이 자바 컬렉션을 사용하는 것처럼 사용할 수 있다.
유지보수 - JPA 필드만 추가하면 됨, SQL 은 JPA 가 처리
기존에 객체 속성이 추가될 때 쿼리문을 모두 수정해주어야하지만, JPA 를 사용한다면, 객체 속성과 DB 컬럼만 추가하여 해결할 수 있다. 즉, 쿼리를 수정할 필요가 없어진다.
JPA 와 상속 - 저장
JPA 사용 시 데이터를 저장하는 과정에서 개발자가 할 일이 아래와 같아지고,
jpa.persist(album);나머지 SQL 쿼리 생성과 같은 일들은 JPA 가 알아서 처리한다.
INSERT INTO ITEM ...
INSERT INTO ALBUM ...JPA 와 상속 - 조회
조회도 마찬가지로 개발자가 할 일이 아래와 같아지고,
Album album = jpa.find(Album.class, albumId);나머진 JPA 가 알아서 처리한다.
SELECT I.*, A.*
FROM ITEM I
JOIN ALBUM A ON I.ITEM_ID = A.ITEM_IDJPA 와 연관관계, 객체 그래프 탐색
아래와 같은 코드로 연관관계 저장 시,
member.setTeam(team);
jpa.persist(member);이후 조회하였을 때 객체 그래프 탐색이 정상적으로 동작한다.
Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam();신뢰할 수 있는 엔티티, 계층
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); //자유로운 객체 그래프 탐색
member.getOrder().getDelivery();
}
}위처럼 SQL 쿼리를 직접 작성하여 조회할 때 보다 자유롭게 객체 그래프를 탐색할 수 있기에, 신회할 수 있는 엔티티를 사용할 수 있다.
JPA 와 비교하기
뿐만 아니라, 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장한다.
String memberId = "100";
Member member1 = jpa.find(Member.class, memberId);
Member member2 = jpa.find(Member.class, memberId);
member1 == member2; //같다JPA의 성능 최적화 - 1차 캐시와 동일성(identity) 보장
같은 트랜잭션 안에서는 같은 엔티티를 반환하여 약간의 조회 성능을 향상하고, DB Isolation Level 이 Read Commit 이어도 애플리케이션에서는 Repeatable Read 를 보장한다.
String memberId = "100";
Member member1 = jpa.find(Member.class, memberId); // SQL
Member member2 = jpa.find(Member.class, memberId); // 캐시
member1 == member2; //같다위처럼 캐시를 통해 SQL 을 1번만 실행해도 된다.
JPA의 성능 최적화 - 트랜잭션을 지원하는 INSERT 지연
transaction.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 모아서 보낸다.
transaction.commit(); // [트랜잭션] 커밋위처럼 트랜잭션을 커밋할 때까지 INSERT SQL 을 모아서 JDBC BATCH SQL 기능을 사용해 한번에 SQL 을 전송한다.
JPA의 성능 최적화 - 트랜잭션을 지원하는 UPDATE 지연
transaction.begin(); // [트랜잭션] 시작
changeMember(memberA);
deleteMember(memberB);
비즈니스_로직_수행(); //비즈니스 로직 수행 동안 DB 로우 락이 걸리지 않는다.
//커밋하는 순간 데이터베이스에 UPDATE, DELETE SQL을 보낸다.
transaction.commit(); // [트랜잭션] 커밋위처럼 UPDATE, DELETE로 인한 로우(ROW)락 시간을 최소화하고, 트랜잭션 커밋 시 UPDATE, DELETE SQL 실행하고, 바로 커밋한다.
JPA의 성능 최적화 - 지연 로딩과 즉시 로딩
Member member = memberDAO.find(memberId);
// SELECT * FROM MEMBER 실행
Team team = member.getTeam();
String teamName = team.getName();
// SELECT * FROM TEAM 실행지연 로딩은 객체가 실제 사용될 때 로딩되어 사용할 수 있도록 최적화 된다.
Member member = memberDAO.find(memberId);
// SELECT M.*, T.* FROM MEMBER JOIN TEAM … 실행
Team team = member.getTeam();
String teamName = team.getName();즉시 로딩은 JOIN SQL 로 한번에 연관된 객체까지 미리 조회하여 사용할 수 있도록 최적화 된다.
ORM 은 객체와 RDB 두 기둥 위에 있는 기술
ORM 을 잘 사용하기 위해선 OOP 와 RDB 에 대한 지식 모두 중요하다. OOP 언어는 RDB 에 비해 변할 가능성이 높기 때문에 RDB 에 대한 공부를 꾸준히 하자!
Hello JPA - 프로젝트 생성
pom.xml 라이브러리 추가
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>jpa-basic</groupId>
<artifactId>ex1-hello-jpa</artifactId>
<version>1.0.0</version>
<dependencies>
<!-- JPA 하이버네이트 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.3.10.Final</version>
</dependency>
<!-- H2 데이터베이스 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>2.1.214</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
</project>persistence.xml JPA 설정하기
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="javax.persistence.jdbc.user" value="sa"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments" value="true"/>
<!--<property name="hibernate.hbm2ddl.auto" value="create" />-->
</properties>
</persistence-unit>
</persistence>데이터베이스 방언
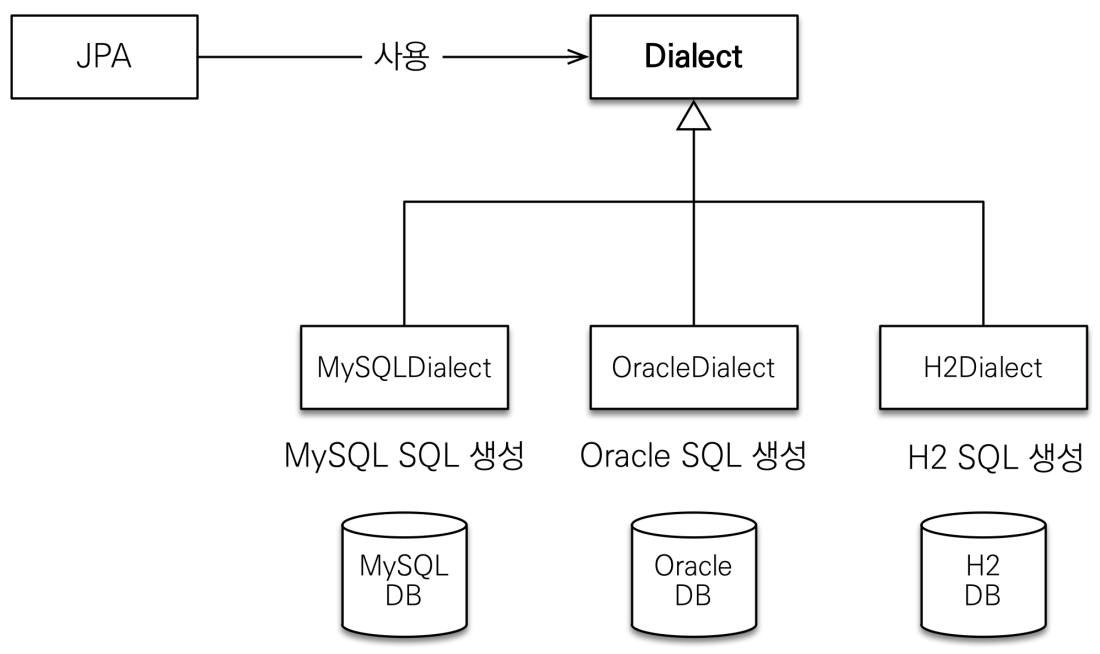 JPA 는 특정 데이터베이스에 종속적이지 않다.
각각의 데이터베이스가 제공하는 SQL 문법과 함수는 조금씩 다르다.
예를 들어, MySQL 은 VARCHAR, Oracle 은 VARCHAR2 를 사용한다.
즉, 방언은 SQL 표준을 지키지 않는 특정 데이터베이스만의 고유한 기능을 의미한다.
JPA 에서는
JPA 는 특정 데이터베이스에 종속적이지 않다.
각각의 데이터베이스가 제공하는 SQL 문법과 함수는 조금씩 다르다.
예를 들어, MySQL 은 VARCHAR, Oracle 은 VARCHAR2 를 사용한다.
즉, 방언은 SQL 표준을 지키지 않는 특정 데이터베이스만의 고유한 기능을 의미한다.
JPA 에서는 hibernate.dialect 속성에 지정하여 특정 데이터베이스 방언을 설정할 수 있다.
- H2 : org.hibernate.dialect.H2Dialect
- Oracle 10g : org.hibernate.dialect.Oracle10gDialect
- MySQL : org.hibernate.dialect.MySQL5InnoDBDialect
Hello JPA - 애플리케이션 개발
JPA 구동 방식
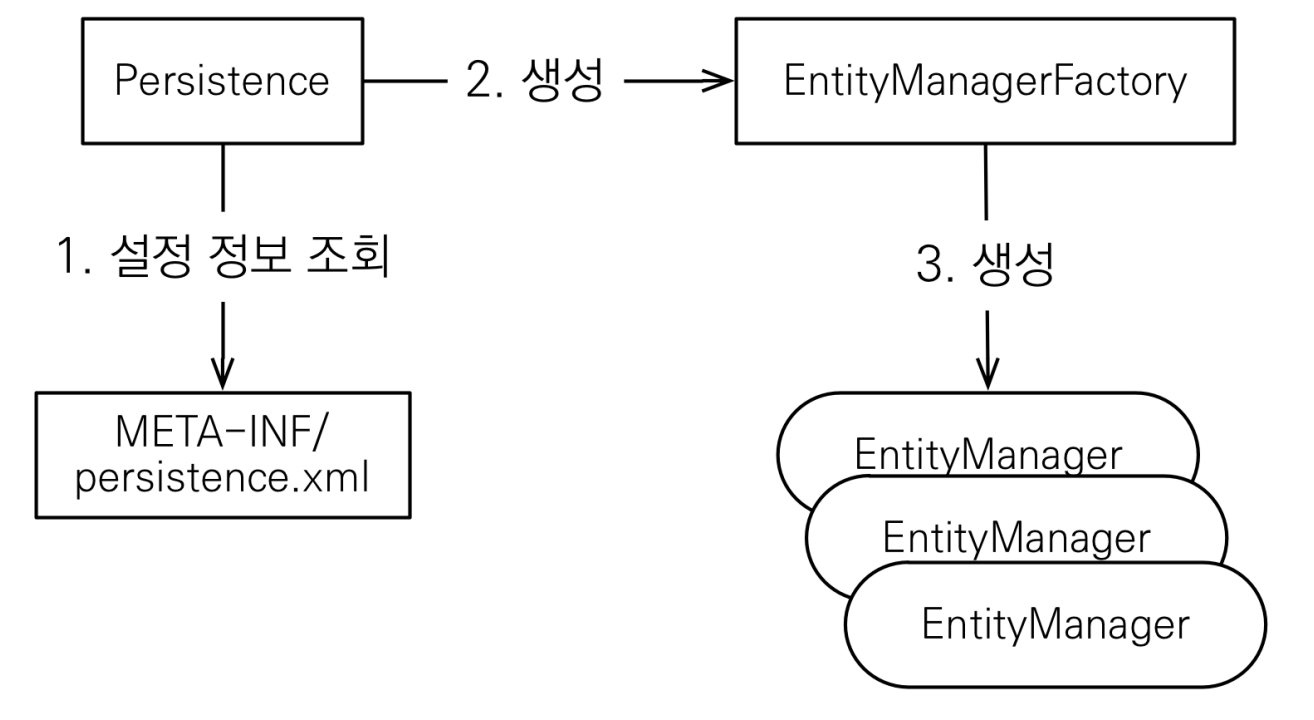
Persistence 라는 클래스에서 설정 파일인 persistence.xml 을 읽어서 EntityManagerFactory 를 생성한다. 이후 EntityManagerFactory 에서 EntityManager 를 찍어내서 사용한다.
객체와 테이블을 생성하고 매핑해보자
package hellojpa;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity // JPA 가 관리할 객체를 의미한다.
public class Member {
@Id // 데이터베이스의 PK 와 매핑한다.
private Long id;
private String name;
// Getter, Setter …
}create table Member (
id bigint not null,
name varchar(255),
primary key (id)
);회원 등록하기
public static void main(String[] args) {
// persistence.xml 에 있는 persistence-unit name 값을 넣어준다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
// code 작성
try {
// 영속
Member member = em.find(Member.class, 150L);
member.setName("ZZZZZ");
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}주의
- 엔티티 매니저 팩토리는 하나만 생성해서 애플리케이션 전체에서 공유한다.
- 엔티티 매니저는 쓰레드간 공유되지 않기 때문에 사용하고 버려야 한다.
- JPA 의 모든 데이터 변경은 트랜잭션 안에서 실행된다.
JPQL
JPA 를 사용하면 엔티티 객체를 중심으로 개발을 진행하게 된다.
특정 엔티티 검색 시에 em.find() 로 단순히 조회하거나 a.getB().getC() 와 같이 객체 그래프 탐색을 통해 조회를 수행할 수 있다.
문제는 조건이 포함된 검색 쿼리를 전송할 때 발생한다.
조건이 포함된 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색하기 때문에 모든 DB 데이터를 객체로 변환해서 검색하는 것은 비효율적이다.
애플리케이션이 필요한 데이터만 DB 에서 불러오려면 결국 검색 조건이 포함된 SQL 이 필요하다.
즉, DB 에 종속적으로 설계가 될 수 밖에 없다는 의미다.
이를 해결하기 위해 JPA 는 SQL 을 추상화한 JPQL 이라는 객체 지향 쿼리 언어 제공한다.
SQL 이 DB 의 테이블을 대상으로 쿼리를 날린다면, JPQL 은 엔티티 객체를 대상으로 쿼리를 날린다.
JPQL 은 테이블이 아닌 객체를 대상으로 하는 객체 지향 쿼리이기 때문에 방언 설정에 맞춰서 각 DB 에 맞게 번역하여 쿼리를 전송한다.
이는 JPQL 이 SQL 을 추상화하기 때문에 특정 데이터베이스 SQL 에 의존하지 않는다는 의미이기도 하다.