Performance Test
성능 테스트의 목적
서비스를 운영하다보면 현재 아키텍처의 가용성에 대한 고민이 자연스럽게 따라옵니다. 가용성을 높인다는 것은 서비스의 안정적인 운영을 보장한다는 의미이기도 합니다. 때문에 고가용성 아키텍처를 구성하는 것은 안정적인 서비스 운영을 위해 필수적입니다.
시스템의 가용성을 확인하기 위해선 일정 수준의 트래픽이 일정 기간 요구됩니다. 하지만 이제 막 시작하는 서비스나 소규모 프로젝트 같은 경우엔 해당 조건을 충족하기엔 어려운 환경을 가지고 있습니다. 이를 해결하기 위해 성능 테스트라는 방법을 활용하여 아키텍처의 가용성을 시험해 볼 수 있습니다.
성능 테스트의 종류
성능 테스트는 시스템의 응답 성능과 한계치를 파악하기 위한 테스트입니다. 현재 시스템 아키텍처가 어느 정도의 부하를 견딜 수 있는지 파악한 후 대응법을 구안하고 병목 발생 지점을 파악한 후 개선 방안을 구안하는데 주로 수행됩니다.
이러한 성능 테스트에도 여러 종류가 존재합니다. 대표적으로 Smoke Test Load Test Stress Test 등이 있습니다. 이번 글에서는 간단하게 Load Test 와 Stress Test 를 경험해보며 WAS 의 적절한 튜닝과 스케일 아웃을 통해 시스템 성능을 어떻게 개선할 수 있는지 기록해보도록 하겠습니다.
성능 테스트 도구
성능 테스트를 수행하는 것을 도와주는 여러가지 도구들이 존재하는데요. 대표적으로 nGrinder JMeter k6 locust 등이 있습니다. 이번 글에서는 한글을 지원하고 Groovy 스크립트를 통해 간편하게 시나리오를 작성할 수 있으며 사용 경험이 있는 nGrinder 를 통해 성능 테스트를 진행했습니다.
팀 내에서 성능 테스트를 진행하면서 시스템 성능을 실시간으로 모니터링하고자 하는 니즈가 있었는데요. 이를 위해 추가적으로 Pinpoint 를 적용하여 모니터링을 진행했습니다.
중요 지표
성능 테스트를 진행하면서 자주 등장하는 지표가 있는데요. 같은 의미이지만 다른 용어로 혼용되는 부분이 많을 수 있어 먼저 간단하게 정리하고 글을 이어나가고자 합니다.
- Throughput, 처리량입니다. TPS 혹은 RPS 등으로도 많이 사용될 예정입니다.
- Latency, 지연율입니다. MTT 등으로 많이 사용될 예정입니다.
Load Test
Load Test, 부하 테스트는 평소 트래픽과 최대 트래픽 시나리오에서 시스템의 성능을 확인하기 위한 성능 테스트입니다. 즉, 시스템의 성능을 확인하고 기대 성능에 도달하기 위해 수행하는 테스트입니다.
시스템이 실제 서비스 중이라고 가정하고 성능을 확인 및 개선하기 위한 테스트인 만큼 너무 낮거나 너무 높은 수치의 부하는 서버가 충분한 부하를 견디지 못하거나 너무 많은 비용을 초래할 수 있기 때문에 적절한 수준의 부하를 지정하는 것이 중요합니다.
Load Test 를 수행하기 위한 특정 수준의 트래픽을 생성하기 위해선 테스트 도구에서 가상 유저의 역할을 하는 VUser 스레드 개수를 지정하여 만족할 수 있습니다. 리틀의 법칙을 응요한 VUser 를 구하는 공식은 아래와 같습니다.
VUser 를 계산하기 위해선 RPS, Request Per Second 를 먼저 계산해야 하는데요. 아마존 웹 서비스 부하 테스트 입문 에서 소개된 RPS 를 구하는 공식은 아래와 같습니다.
목표하는 DAU 와 예상하는 1인당 하루 평균 요청 값을 산정하여 RPS 를 계산한 뒤 VUser 를 도출해낼 수 있습니다. 저희 팀에선 월 평균 사용자 수를 서울 자영업자 수인 300,000명으로 산정하여 10,000이라는 DAU 수치를 정하고 하루 5건 정도의 평균 요청이 들어온다는 가정으로 VUser 를 계산하였습니다.
- DAU, 일 평균 사용자 수 = 10,000
- Peak Time Ratio, 피크타임 트래픽 계수 = 10
- Daily Personal Average Request, 1인당 하루 평균 요청 = 5
- http_req_duration, 요청 처리 시간 = 0.5
- Think Time, 인지 시간 = 1
위 정의된 변수들로 계산해보면 RPS 는 0.58 ~ 5.8 로 산정되고 이를 통해 VUser 를 계산해보면 0.64 ~ 6.4 의 값을 도출해낼 수 있습니다.
즉, MAU 가 300,000인 환경을 가정했을 때 VUser 는 0.64 ~ 6.4 정도로 산정되며, VUser 를 7로 설정하여 부하 테스트를 진행했을 때 시스템이 정상적으로 작동할 경우 현재 아키텍처가 300,000 MAU 의 부하를 충분히 감당할 수 있다는 것을 의미합니다.
테스트 환경
일반적으로 성능 테스트는 하나의 API 엔드포인트 마다 테스트를 진행하는 것이 병목 지점을 찾기 용이하기 때문에 현재 서비스에서 가장 트래픽이 많을 것으로 예상되는 Submission 목록 조회 API 를 대상으로 성능 테스트를 진행했습니다.
Submission 목록 조회 API 는 단순 조회 API 이기 때문에 보다 유의미한 결과를 얻기 위해 한달 간 10만개의 데이터가 쌓였다는 가정하에 더미 데이터를 저장한 상태로 진행했습니다.
테스트 결과
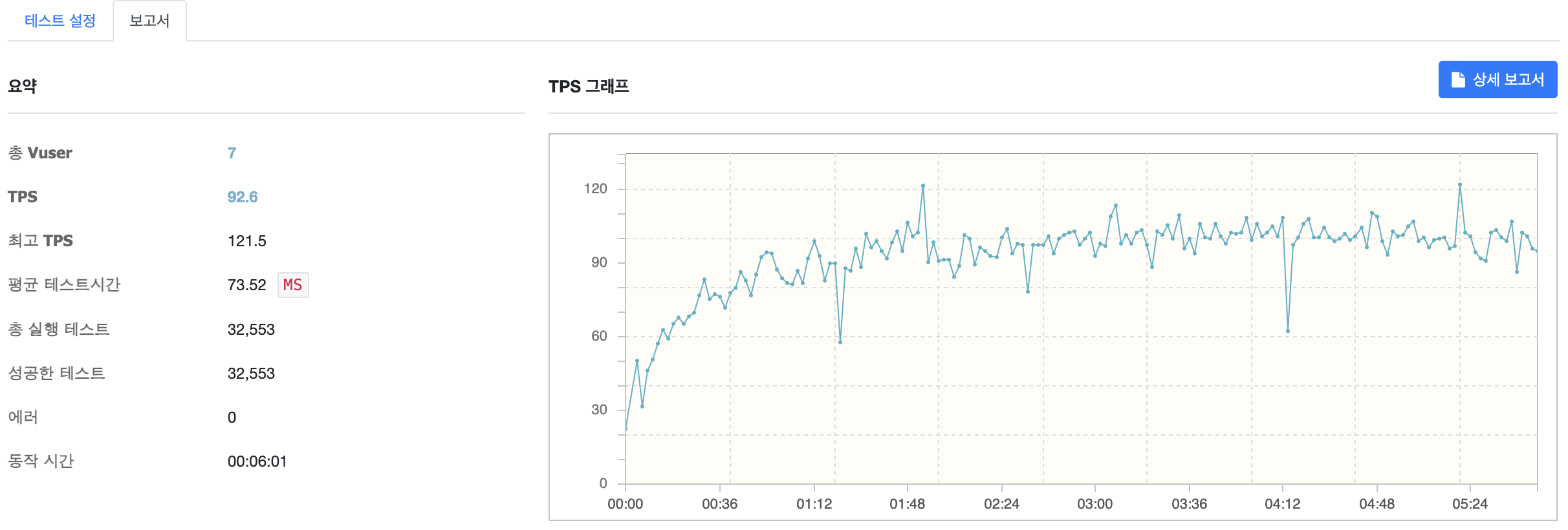
VUser 를 7로 설정한 상태로 부하 테스트를 진행한 결과입니다. 평균 92.6 TPS 와 73.5ms 의 요청 처리 시간을 기록했습니다. 0.1초 이내의 시간으로 초당 92개의 요청을 처리했으니 MAU 가 300,000인 환경에서 계산한 5.8 Peak RPS 를 충분히 웃돌고 남을 수치인 것을 확인할 수 있습니다.
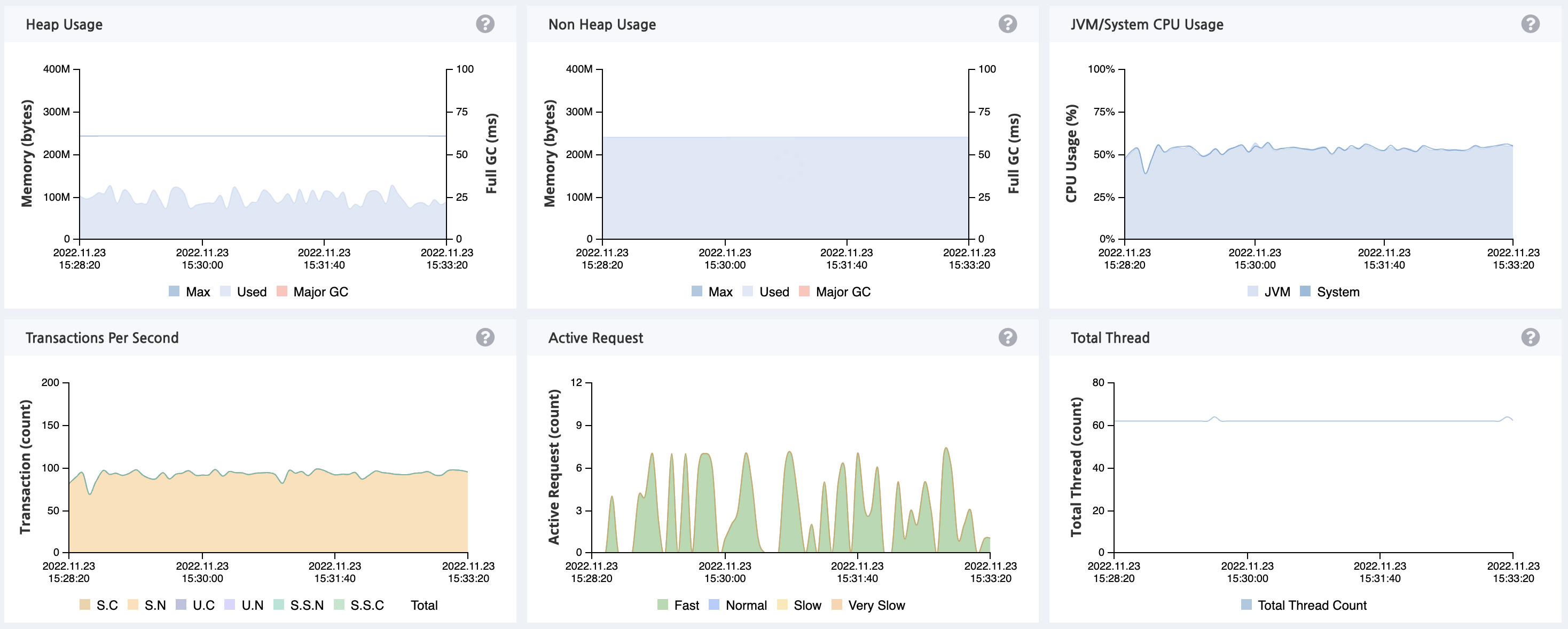
추가적으로 Pinpoint 를 활용한 모니터링 내역입니다. JVM CPU 사용량이 50% 정도인 것을 확인할 수 있습니다. 이는 300,000 MAU 의 트래픽을 큰 무리없이 처리하고 있음을 확인할 수 있는 지표입니다.
Load Test 는 평소 트래픽과 최대 트래픽 상황에서의 시스템의 성능을 측정하고 해당 트래픽 수준에 맞는 최대 성능을 이끌어내기 위하여 수행되기 때문에 해당 트래픽 수준에 맞게 WAS 설정을 적절히 조정하는 작업까지 수행해야 Load Test 의 목적을 달성했다고 볼 수 있습니다.
현재 WAS 는 Spring Boot 로 이루어져 있기 때문에 Tomcat 과 Hikari CP 설정을 적절히 조절하여 성능을 최대로 끌어올려보는 작업을 진행해보겠습니다.
Tomcat Tuning
MaxThread Default 200

Tomcat 의 기본 Thread 개수는 10개입니다. 요청이 많아져 최대로 늘어날 수 있는 Thread 의 개수가 200개 임에도 불구하고 Load Test 를 수행하는 동안 10개를 유지하는 것을 확인할 수 있습니다. 이는 현재 부하 수준에서는 10개가 모두 필요하지 않을 수 있다고 예상해 볼 수 있습니다.
사용하지 않는 Thread 를 생성해두는 것은 부적절한 메모리 사용과 불필요한 Context Switching 을 야기할 수 있기 때문에 기본 Thread 개수를 적당한 개수로 조정하여 Throughput 와 Latency 를 개선할 필요가 있습니다.
그렇다면 어느 정도의 스레드 개수가 적절한 스레드 개수 일까요? 자바 병렬 프로그래밍 에서는 다음과 같은 공식을 통해 적정 스레드 개수를 산정하도록 소개하고 있습니다.
여기서 대기시간과 서비스시간은 각각 실제로 응답까지 걸리는 시간과 실제로 요청을 처리하는 시간입니다.
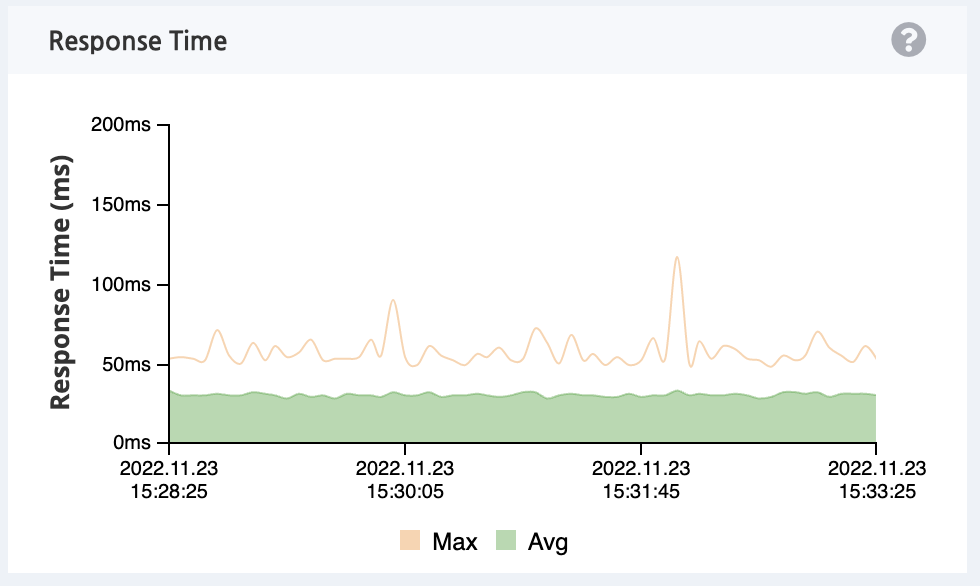
이는 nGrinder 를 통해 수집한 MTT 값과 Pinpoint 를 통해 모니터링한 Response Time 지표를 통해 확인할 수 있습니다. 현재 WAS 가 구동되고 있는 EC2 인스턴스의 스펙은 1GB 의 메모리와 2Core CPU 입니다. 이를 대입하여 계산해보면 2 * (1 + 73.52/40) = 5.676 이 산정됩니다.
실제로 Tomcat Thread Pool 설정을 조정해가며 Load Test 를 다시 수행해보겠습니다.
MaxThread 7
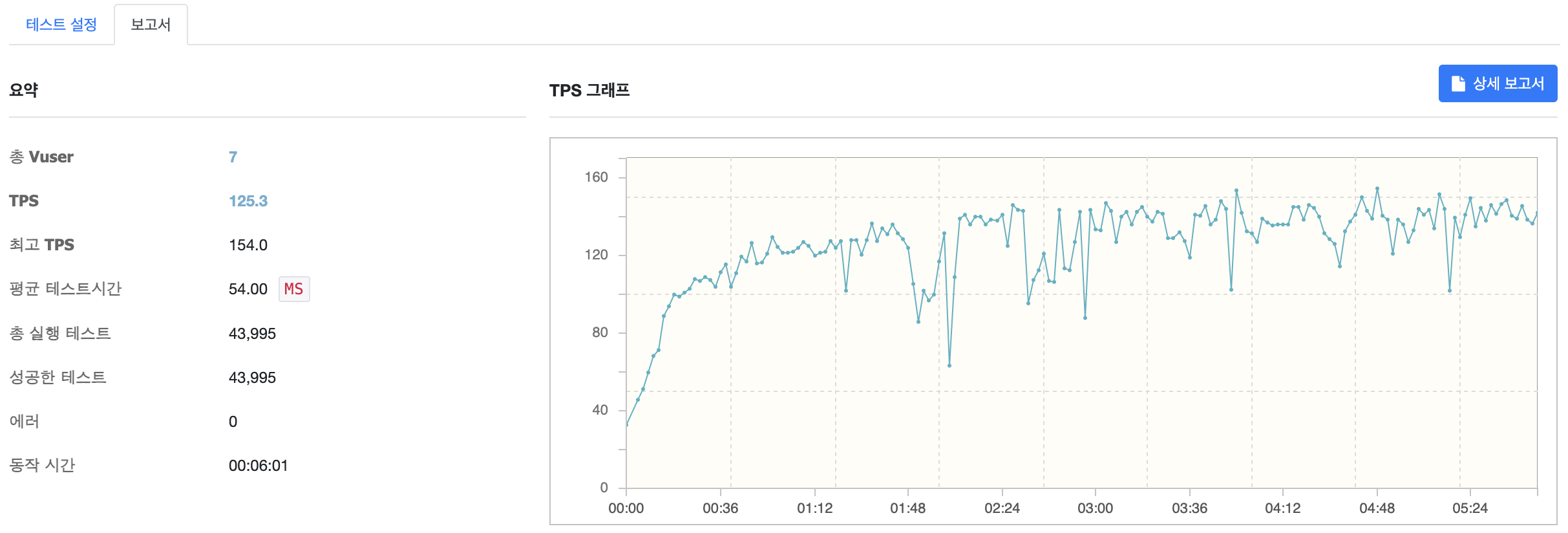
MaxThread 를 7로 설정하고 테스트를 수행한 결과입니다. TPS 가 92.6에서 125.3으로 약 35% 상승한 것을 확인할 수 있습니다.
MaxThread 5
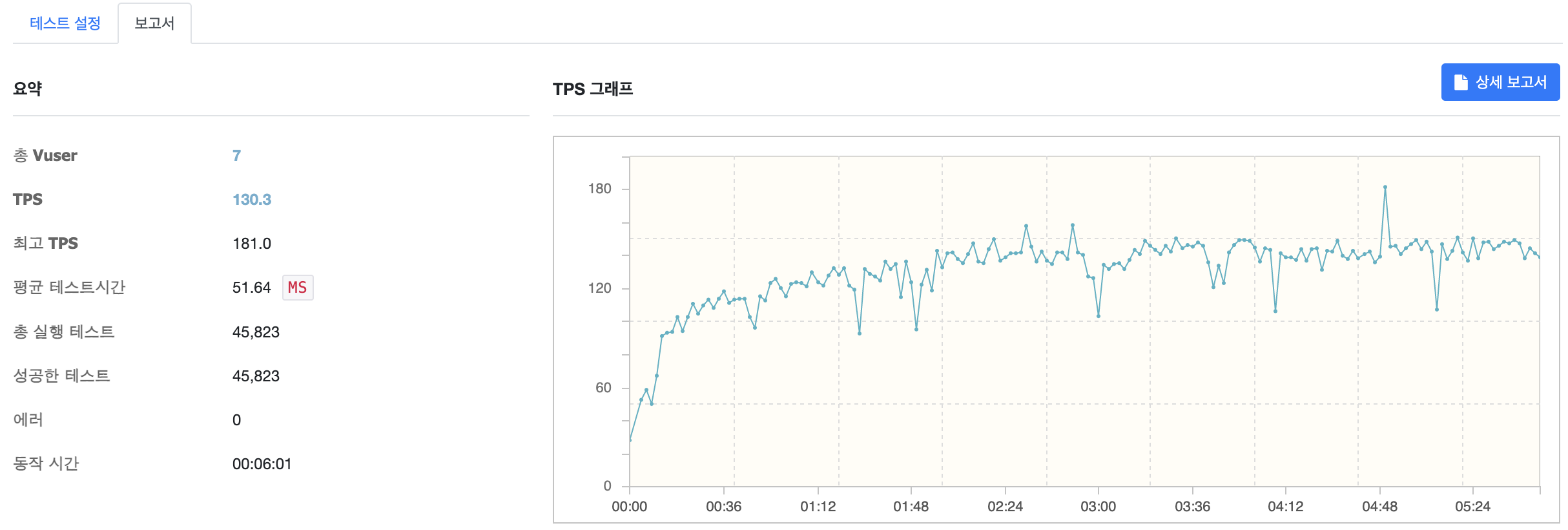
MaxThread 를 5로 설정하고 테스트를 수행한 결과입니다. TPS 가 이번엔 130.3으로 약 40% 상승한 것을 확인할 수 있습니다.
MaxThread 3
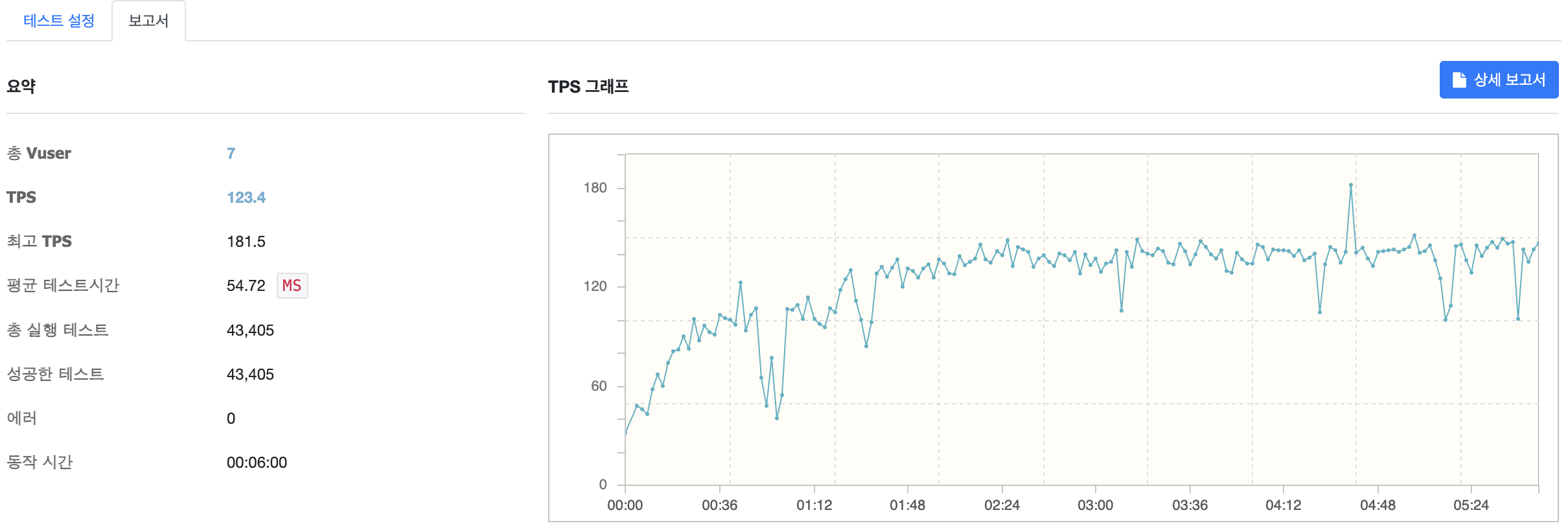
MaxThread 를 3으로 설정하고 테스트를 수행한 결과입니다. TPS 가 이번엔 오히려 감소한 것을 확인할 수 있습니다.
이를 통해 공식을 통해 계산한 것과 비슷하게 MaxThread 5가 가장 적절한 값임을 확인할 수 있었습니다.
Hikari CP Tuning
두 번째로 조정해볼 수 있는 지점은 DB 커넥션을 관리하는 Hikari CP 의 Connection Pool Size 입니다.
Hikari CP 공식문서에 따르면 아래 공식을 통한 Connection Pool Size 가 가장 적절하다고 소개합니다.
여기서 CoreCount 는 Cloud 환경에서 논리 CPU 개수와 동일하고 EffectiveSpindleCount 는 하드 디스크와 관련이 있습니다. EC2 인스턴스의 경우 하드 디스크가 아닌 SSD 를 사용하기 때문에 Connection 은 5가 가장 적절하다고 판단됩니다.
추가적으로 우아한형제들 기술블로그에서 소개된 데드락을 방지하기 위한 PoolSize 계산 공식입니다. 데이터베이스와 통신을 위한 Connection 은 요청을 처리하는 Thread 와 큰 관련이 있기 때문에 PoolSize 는 항상 Thread 보다 적은 값을 유지하는 것이 좋다고 소개합니다.
MaxConnectionPoolSize 5
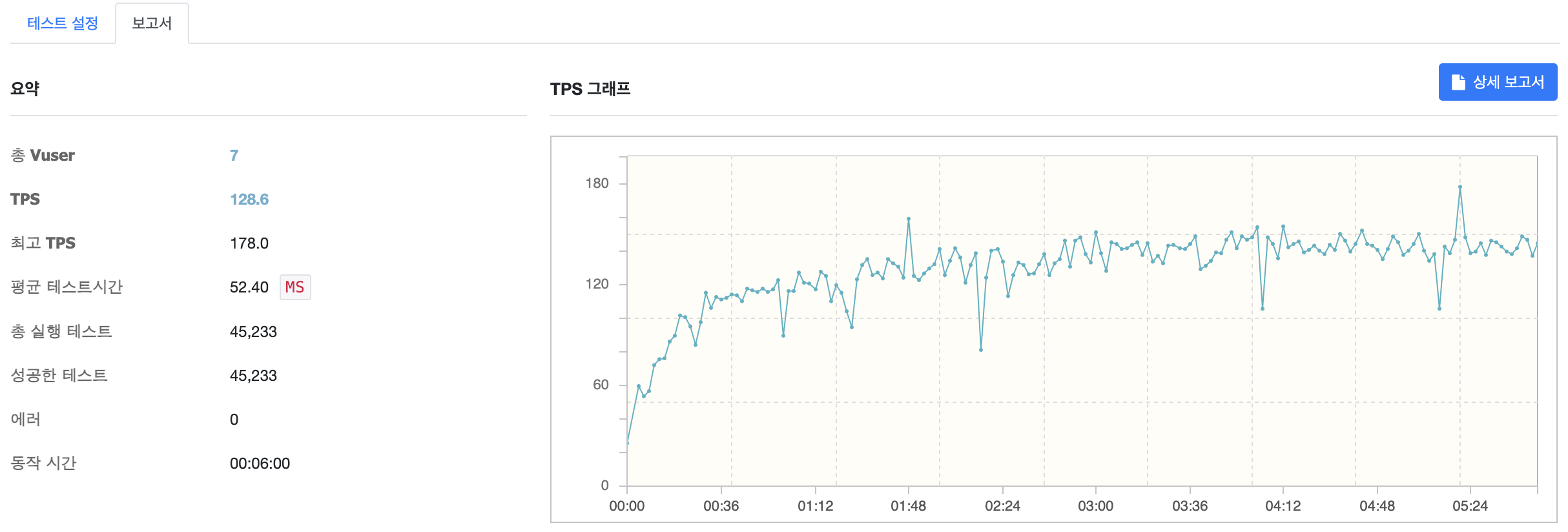
MaxConnectionPoolSize 를 5로 설정한 뒤 테스트를 진행한 결과입니다. TPS 가 소량 감소했지만 큰 변화폭은 없는 것을 확인할 수 있습니다.
MaxConnectionPoolSize 6
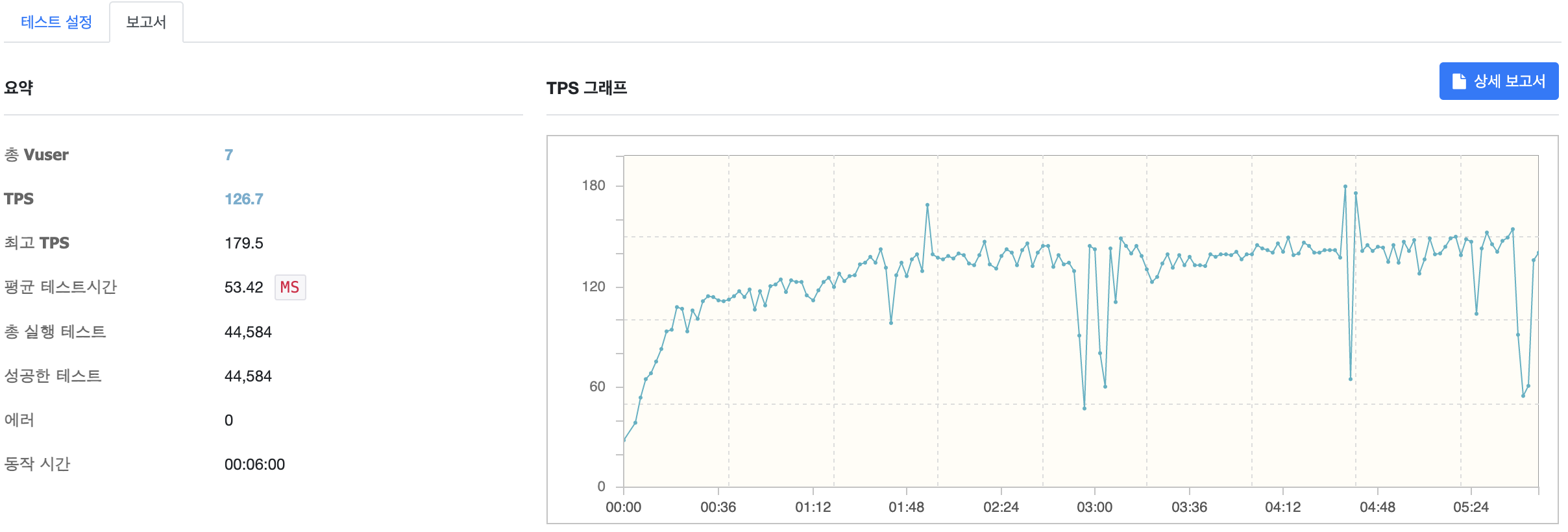
MaxConnectionPoolSize 를 6으로 설정한 뒤 테스트를 진행한 결과입니다. PoolSize 를 증가해도 크게 의미있는 수치가 나오지 않았기 때문에 Thread 개수와 가장 근접한 5개로 유지하는 것이 좋을 것이라고 판단하였습니다.
이로써 300,000 MAU 환경에서의 WAS 설정을 모두 마무리할 수 있었습니다. Tomcat Thread 와 Hikari CP 를 5로 설정함으로써 TPS 를 92.6에서 130.3으로 약 40% 개선했으며 MTT 또한 73.52에서 51.64으로 현저히 줄어든 것을 확인할 수 있었습니다.
Stress Test
Saturation Point
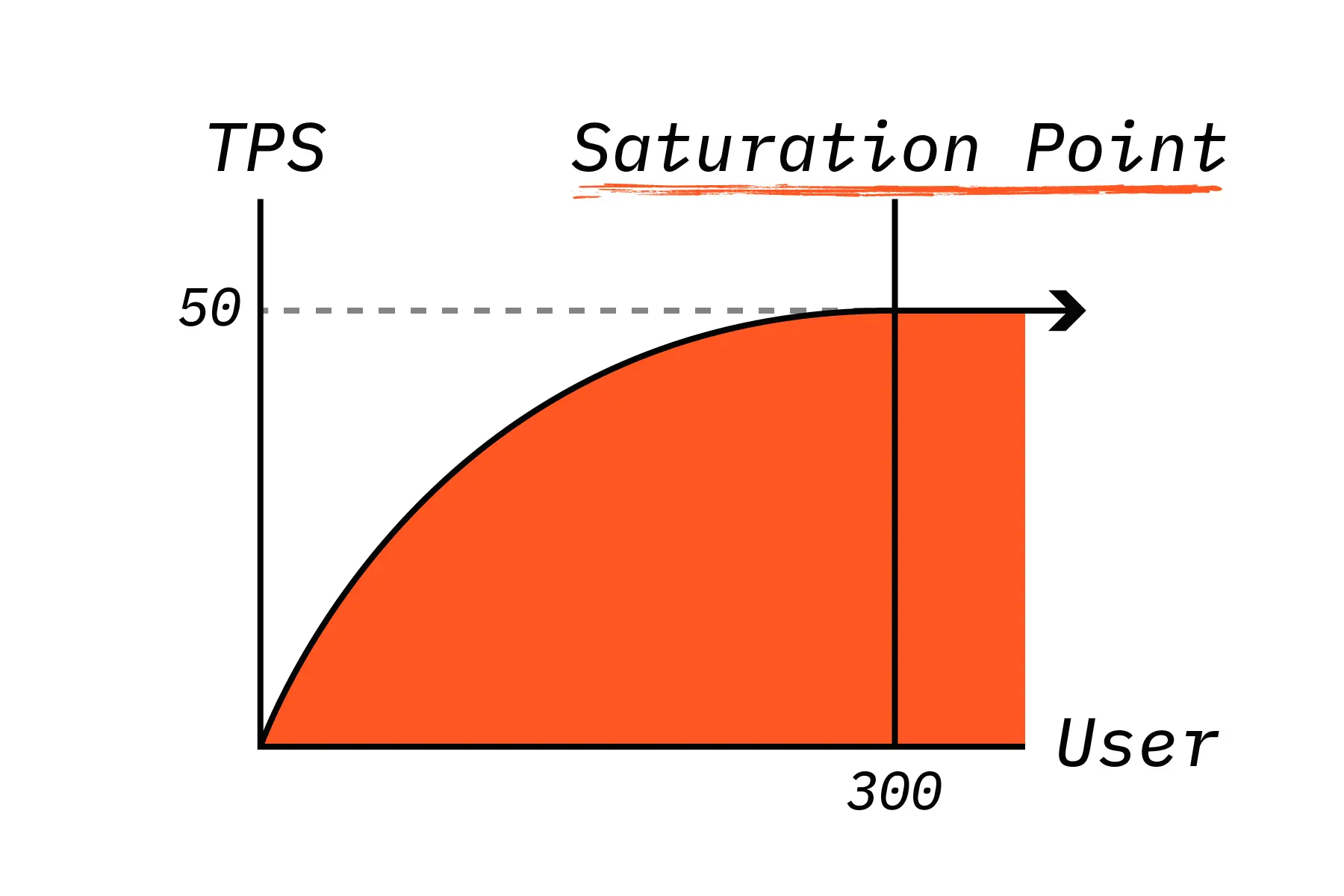
Stress Test 가 최대 처리량과 한계점을 확인하는 테스트인 만큼 Saturation Point 의 대한 이해가 중요한데요. 시스템의 부하가 늘어남에 따라 TPS 역시 증가하게 되는데 어느 순간부터 TPS 는 정체되고 Latency 만 증가하는 지점이 발생합니다. 이를 Saturation Point, 한계점이라고 합니다.
Saturation Point 를 찾음으로써 현재 아키텍처의 한계를 파악하고 스케일 업 또는 스케일 아웃등의 방법을 통해 시스템의 처리량을 늘리는 방안을 고려할 수 있습니다. 이는 갑작스러운 대량의 트래픽이 발생했을 때 서비스가 다운되지 않고 오토 스케일링 등을 통해 높은 가용성을 확보하기 위해 매우 중요한 지표입니다.
테스트 결과
이번에 진행한 Stress Test 는 Tomcat Thread 와 Hikari Connection Pool 설정값을 모두 기본값인 상태로 진행했습니다.
| VUser | TPS | MTT |
|---|---|---|
| 7 | 92.6 | 73.5 |
| 10 | 107.9 | 90.6 |
| 15 | 145.9 | 100.6 |
| 20 | 151.6 | 129.8 |
| 30 | 152.9 | 194.1 |
| 50 | 163.3 | 303.0 |
| 200 | 167.1 | 1195.82 |
| 300 | 165.0 | 1816.47 |
| 400 | 164.9 | 2435.25 |
| 1000 | 158.0 | 6380.3 |
위 결과를 통해 알 수 있는 것은 VUser 가 200이 넘어가는 지점부터 점점 TPS 가 감소되는 것을 통해 현재 아키텍처의 Saturation Point 는 VUser 가 200인 지점인 것을 알 수 있습니다.
VUser 15
기존에 정상적인 서비스가 가능하다고 정의했던 MTT 는 100ms 이었기 때문에 실질적으로 VUser 가 15일 때 현재 아키텍처가 가장 정상적으로 동작할 수 있는 상태라고 볼 수 있습니다.
실제로 Pinpoint 를 통해 모니터링 해본 결과 CPU 사용량은 100% 에 거의 다다르고 있습니다.
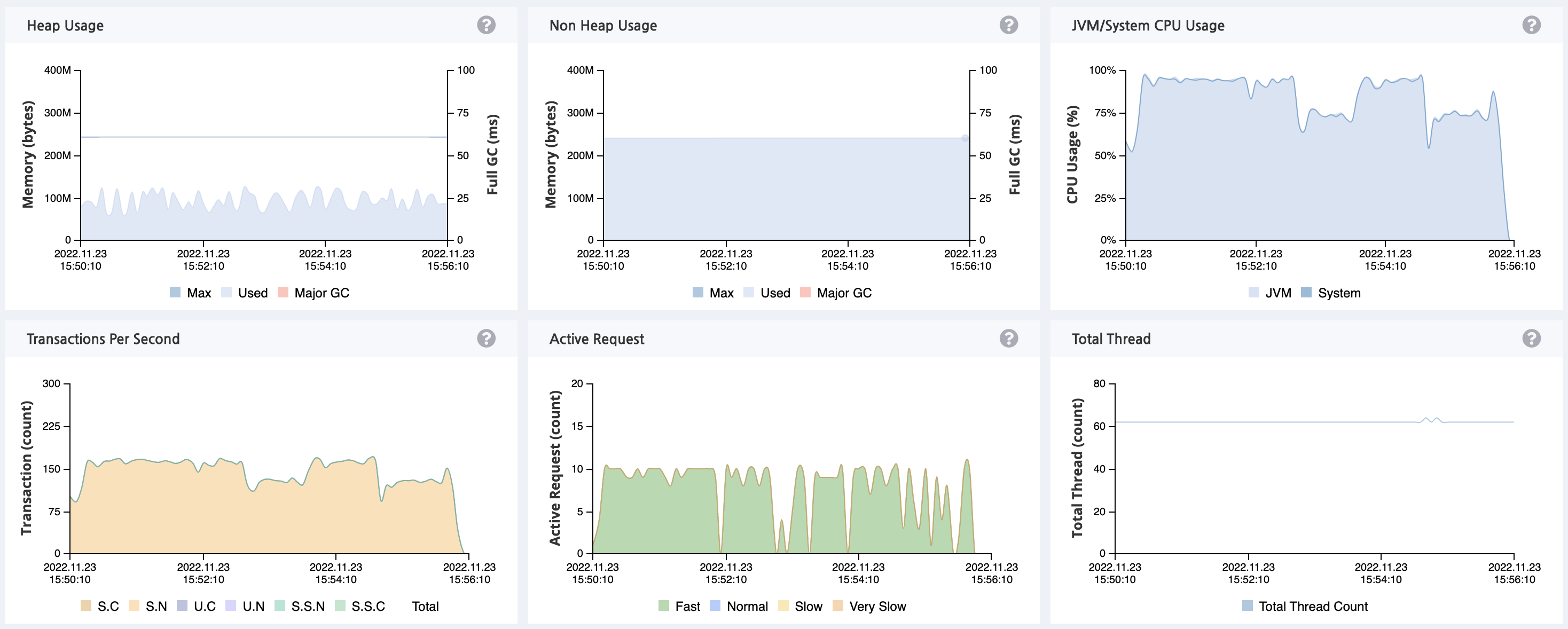
VUser 50
VUser 가 50을 넘어서자 CPU 사용량이 100% 로 과부화 상태에 걸린 것을 확인할 수 있습니다.
이를 해결하기 위해 스케일 업 또는 스케일 아웃 등의 방법을 생각해볼 수 있는데요. 이번엔 간단하게 WAS 한 대를 추가하고 로드 밸런싱을 통해 스케일 아웃 하는 작업을 진행한 뒤 TPS 를 다시 측정해보겠습니다.
Scale Out
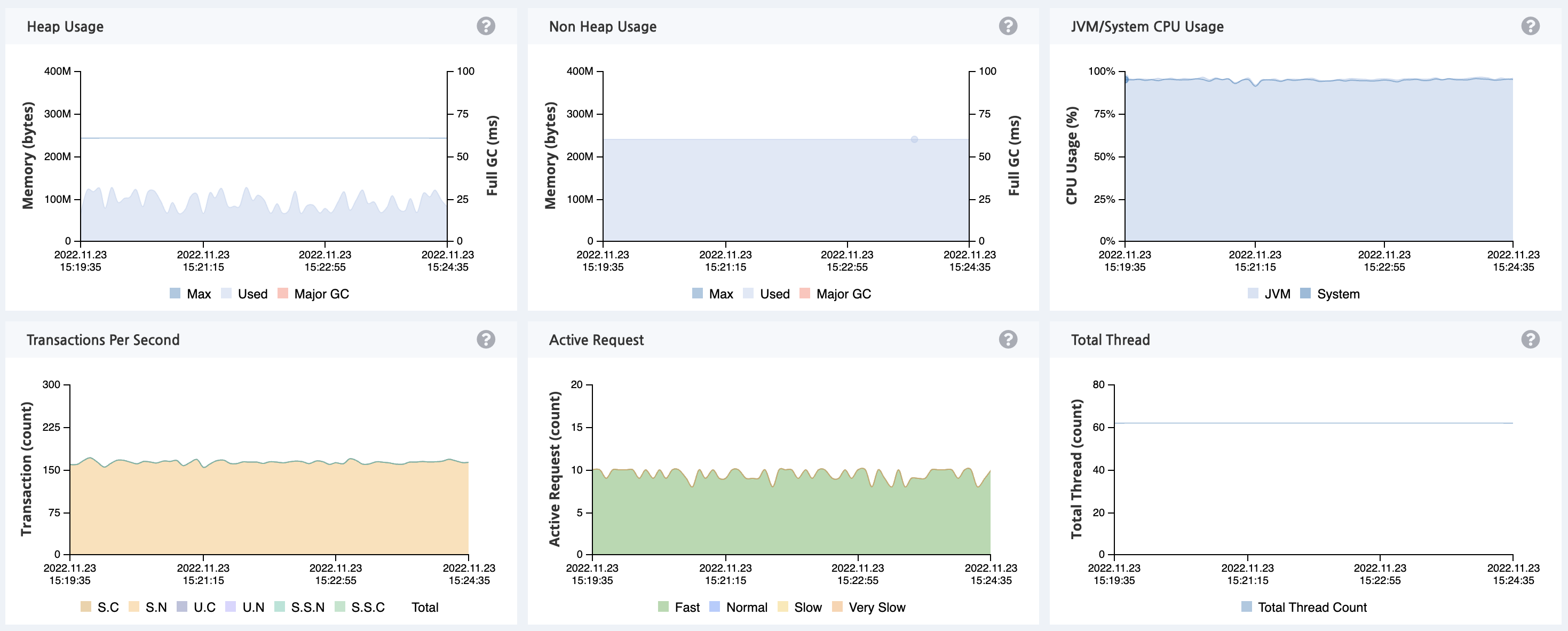
VUser 50
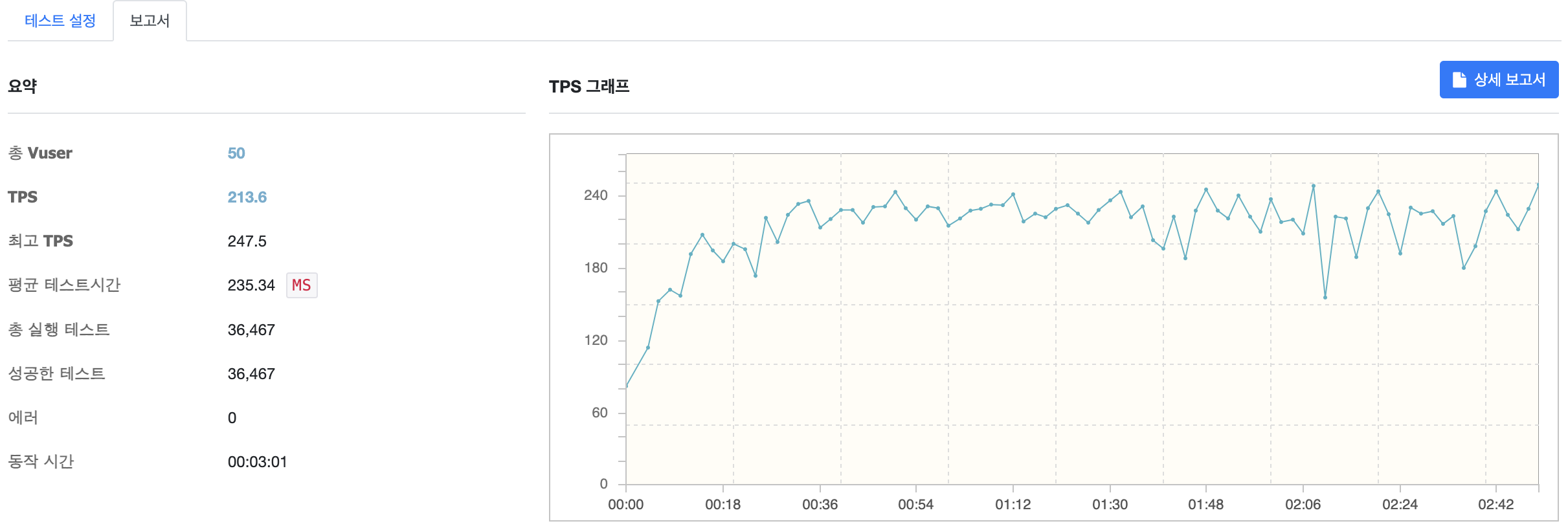
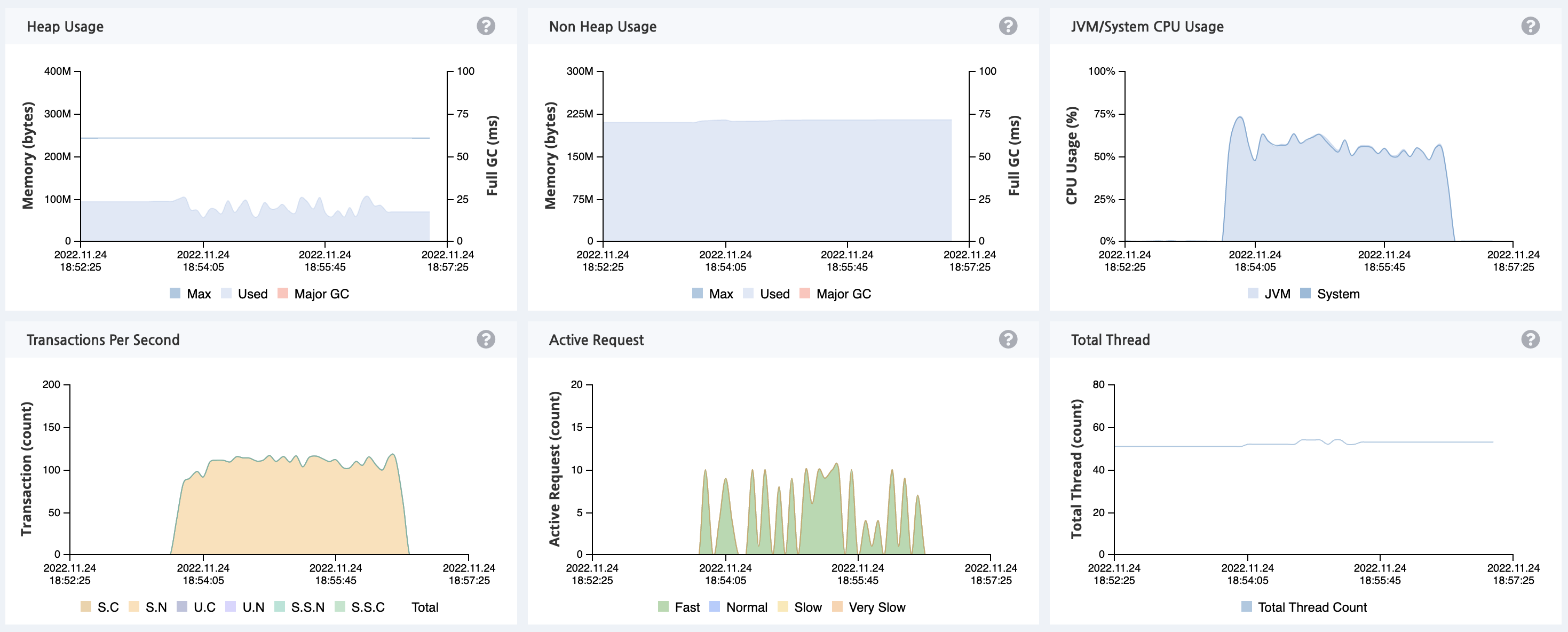
기존에 한 대의 WAS 를 사용했을 때 CPU 사용량이 100% 로 과부화 상태에 걸린것에 비해 로드 밸런싱을 통해 스케일 아웃을 하자 CPU 사용량이 65% 정도로 현저히 줄어든 것을 확인할 수 있었고, TPS 역시 기존 163.3에서 213.6으로 약 30% 상승한 것을 확인할 수 있습니다. 추가적으로 기존에 303.0의 MTT 를 기록한 반면 이번엔 235.34로 약 22% 개선된 것을 확인할 수 있습니다.
VUser 300
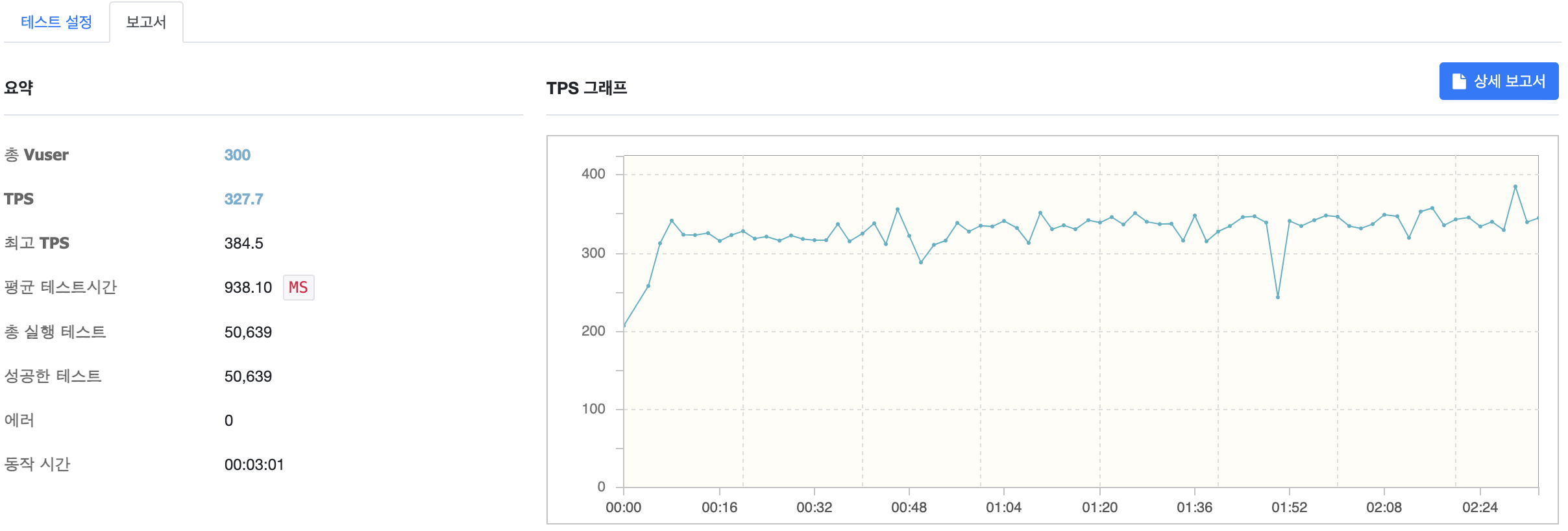
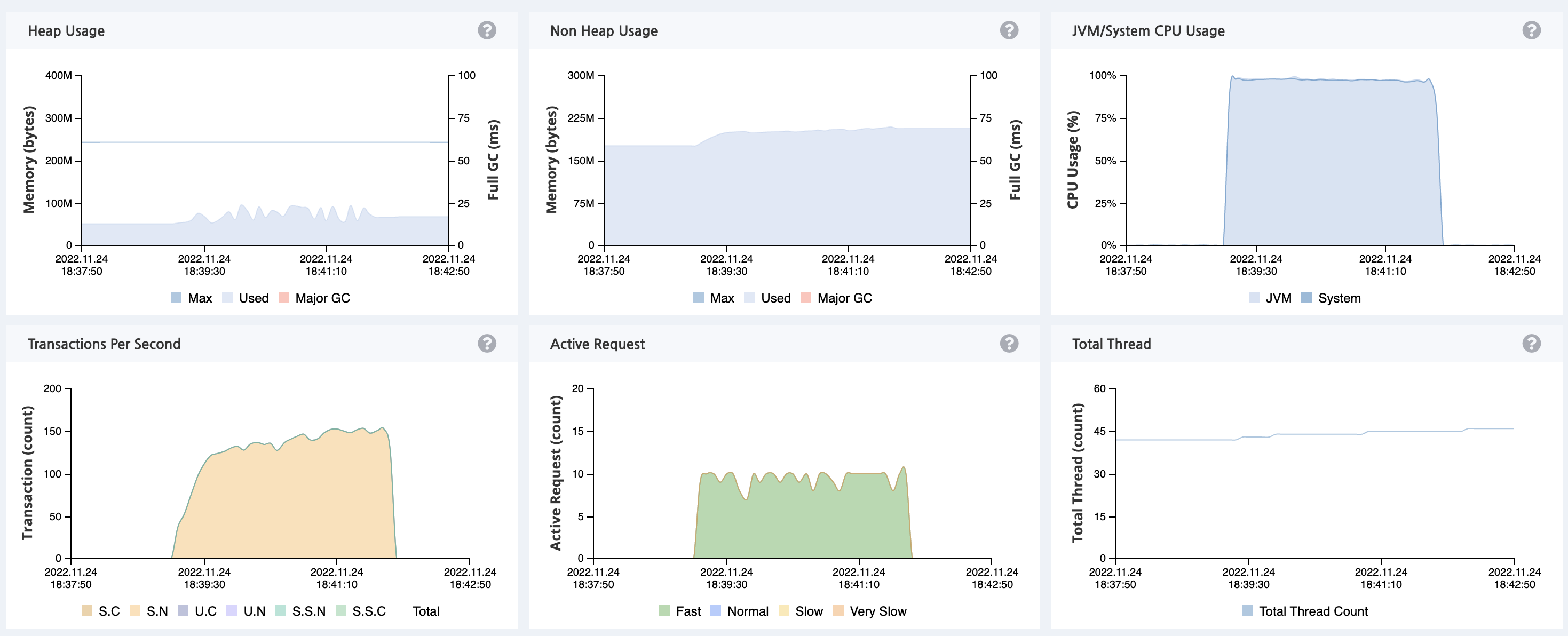
점진적으로 부하를 늘려 VUser 가 300 이 되자 CPU 사용량이 100% 로 과부화에 진입하는 것을 확인할 수 있습니다.
테스트 결과
| VUser | TPS | MTT |
|---|---|---|
| 50 | 213.6 | 235.34 |
| 300 | 327.7 | 938.10 |
| 400 | 347.4 | 1190.36 |
| 500 | 316.6 | 1631.64 |
| 1000 | 303.1 | 3143.82 |
스케일 아웃을 통해 요청을 처리하는 WAS 가 이중화되자 Saturation Point 는 VUser 가 400 이 되는 지점까지 증가했고 TPS 와 MTT 역시 상당히 많이 개선된 것을 확인할 수 있습니다.
마주친 문제들
Pinpoint Agent 와 같이 실행 시 G1GC 가 적용되지 않는 이슈
sudo nohup java -XX:+UseG1GC -XX:+DisableExplicitGC -XX:MaxGCPauseMillis=200 -jar -javaagent:pinpoint-agent-2.2.2/pinpoint-bootstrap-2.2.2.jar -Dpinpoint.agentId=gongcheck-dev -Dpinpoint.applicationName=GONGCHECK-DEV -Dpinpoint.config=pinpoint-agent-2.2.2/pinpoint-root.config deploy/gong-check-0.0.1-SNAPSHOT.jar --spring.profiles.active=dev 2>> /dev/null >> /dev/null &모니터링을 위해 Pinpoint Agent 와 함께 서버를 실행하자 Java 11 의 기본 GC 인 G1GC 가 아닌 Serial GC 가 적용되는 이슈가 있었습니다. 때문에 STW 가 더 자주 발생하여 제대로 된 성능 테스트를 수행할 수 없었고 서버 실행 시 직접 G1GC 를 적용해줌으로써 정상적인 성능 테스트를 수행할 수 있었습니다.
마무리
지금까지 nGrinder 를 통해 Load Test 와 Stress Test 를 수행하고 Pinpoint 모니터링과 함께 Tomcat 과 Hikari CP 설정을 튜닝해보는 경험을 소개해드렸습니다. 처음 수행해보는 성능 테스트였기에 오점도 조금씩 보이고 아쉬운 부분이 많은 것 같습니다. 그래도 성능 테스트에 대한 이해와 직접 WAS 를 튜닝해보는 경험 등을 통해 Tomcat, Hikari CP, JVM, GC 등 많은 것을 학습할 수 있었던 것 같습니다.