Manual Scheduling
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 8080
nodeName:Pod 를 생성하면 위 처럼 nodeName 이 빈 칸인 상태가 K8s memory 에 저장된다. kube-scheduler 는 생성된 Pod 중 scheduling 대상이 될 Pod 들을 nodeName 필드가 빈 칸인 것을 통해 찾아낸다. 이후 scheduling algorithm 으로 Pod 를 배치할 적절한 Node 를 찾아낸 후 Pod 를 배치한 뒤 nodeName 에 Node 의 이름을 추가한다.
apiVersion: v1
kind: Binding
metadata:
name: nginx
target:
apiVersion: v1
kind: Node
name: node02curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind":"Binding", ...}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
만약 kube-scheduler 가 실행 중이지 않다면 Pod 를 생성해도 Pending 상태로 Pod 가 작동하지 않는다. 때문에 수동으로 Pod 를 scheduling 하고 싶은 경우 직접 nodeName 을 지정해준 상태로 Pod 를 생성하거나, Pod 가 이미 생성된 경우 위 처럼 Binding 을 만들고 curl 요청을 통해 동적으로 Pod 를 배치할 수도 있다.
Labels and Selectors
apiVersion: v1
kind: Pod
metadata:
name: simple-webapp
labels:
app: App1
function: Front-end
spec:
containers:
- name: simple-webapp
image: simple-webapp
ports:
- containerPort: 8080Label 은 여러 K8s Object 중 관련된 Object 들만 찾아내기 위해 사용자가 지정한 일종의 별명과 같다. 위와 같은 Pod 를 생성하였을 경우,
kubectl get pods --selector app=App1
Selector 옵션을 통해 Label 값이 일치하는 Pod 만 찾아낼 수 있다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: simple-webapp
labels:
app: App1
function: Front-end
spec:
replicas: 3
selector:
matchLabels:
app: App1
template:
metadata:
labels:
app: App1
function: Front-end
spec:
containers:
- name: simple-webapp
image: simple-webapp위와 같은 ReplicaSet 을 생성할 때 metadata.labels 는 해당 ReplicaSet 에 대한 Label 이고, spec.selector.matchLabels 는 ReplicaSet 이 제어할 Pod 을 특정하기 위한 Label 이고, spec.template.metadata.labels 가 ReplicaSet 에 의해 생성될 Pod 의 Label 이다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: App1
ports:
- protocol: TCP
port: 80
targetPort: 9376 Service 도 마찬가지로 spec.selector 를 통해 연결할 Pod 를 특정할 수 있다.
kubectl label nodes node01 color=blue
위 명령어를 통해 Label 을 달아줄 수 있다.
Annotations
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: simple-webapp
labels:
app: App1
function: Front-end
annotations:
buildversion: 1.34
spec:
replicas: 3
selector:
matchLabels:
app: App1
template:
metadata:
labels:
app: App1
function: Front-end
spec:
containers:
- name: simple-webapp
image: simple-webappLabel 은 Selector 를 통해 Object 를 특정하기 위해 쓰이는 반면, Annotation 은 다른 일반적인 정보를 기록하기 위해 쓰인다.
Taints and Tolerations
kubectl taint nodes {node-name} {key}={value}:{taint-effect}
# Taint 설정
kubectl taint nodes node1 app=blue:NoSchedule
# Taint 제거
kubectl taint nodes node1 app=blue:NoSchedule-
Taint 는 Pod 가 특정 Node 에 배치되는 것을 방지하기 위해 사용할 수 있는 설정이다. 위와 같은 명령어를 통해 특정 Node 를 Taint 시킬 수 있다. taint-effect 는 총 3가지로 아래와 같다.
NoSchedule: Tolerant 하지 않은 Pod 는 schedule 되지 않는다. 이미 배치된 Intolerant 한 Pod 는 그대로 실행된다.PreferNoSchedule: 웬만하면 schedule 되지 않지만 보장되진 않는다.NoExecute: Tolerant 하지 않은 Pod 가 제거된다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: nginx-container
image: nginx
tolerations:
- key: "app"
operator: "Equal"
value: "blue"
effect: "NoSchedule"Pod 에 Tolerantion 을 부여하고 싶은 경우, spec.tolerations 에 Taint 와 같은 설정을 지정해주면 된다. kube-scheduler 는 기본적으로 Taint 와 Toleration 을 고려하며 Pod 를 배치하는데, 만약 Pod definition 에 spec.nodeName 필드가 명시되어 있다면 NoSchedule 이어도 scheduling 을 건너뛰고 Pod 가 배치된다. NoExecute 의 경우라면 Pod 가 배치되더라도 제거될 수 있다.
kubectl describe node kubemaster | grep Taint
Master Node 도 사실은 Taint 되어 있어서 Core Component 외 Object 가 배치되지 않는 것이다.
Node Selectors
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: data-processor
image: data-processor
nodeSelector:
size: Large상대적으로 많은 하드웨어 리소스를 요구하는 컨테이너를 적절한 Node 에서 실행하기 위해서 spec.nodeSelector 설정을 활용할 수 있다. Node Selector 역시 label 을 활용해 대상이 될 Node 를 특정할 수 있다.
kubectl label nodes {node-name} {label-key}={label-value}
kubectl label nodes node-1 size=Large
위와 같은 커맨드로 특정 Node 에 label 을 달아주고 Pod definition file 에서 해당 label 을 가진 Node 를 지정해준 뒤 생성하면 원하는 Node 에 Pod 를 실행할 수 있다.
다만 spec.nodeSelector 설정은 단순히 label 만 확인하기 때문에 더 복잡한 조건으로 Node 를 설정하고 싶을 때 Node Affinity 를 활용할 수 있다.
Node Affinity
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: data-processor
image: data-processor
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In
values:
- Large
- Medium위와 같이 Node Affinity 를 사용하면 size In Large, size NotIn Small, size Exists 등 더 복잡한 조건문을 통해 Pod 가 배치될 Node 를 지정할 수 있다. Pod 가 배치될 적절한 Node 를 찾기 위해 requiredDuringSchedulingIgnoredDuringExecution 과 같은 설정값을 줄 수 있는데,
- Available
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
- Planned
requiredDuringSchedulingRequiredDuringExecutionpreferredDuringSchedulingRequiredDuringExecution현재 2가지가 제공되고 추후 2가지가 더 추가될 예정이다. 해당 설정은 이름 그대로 작동하는데,DuringScheduling은 Pod 가 Schedule 되는 시점에 Node 에 알맞는 label 이 있는지 확인하는 것이고DuringExecution은 Node 가 Pod 를 호스팅하는 중 label 이 변경되었을 시 처리를 지정하는 것이다. 예를 들어,preferredDuringSchedulingIgnoredDuringExecution은 웬만하면 Node label 이 설정된 곳에 Pod 를 배치하고 싶다는 것이고, 배치된 이후 Node label 이 변경되더라도 그대로 호스팅해달라는 의미다.
Taints and Tolerations vs Node Affinity
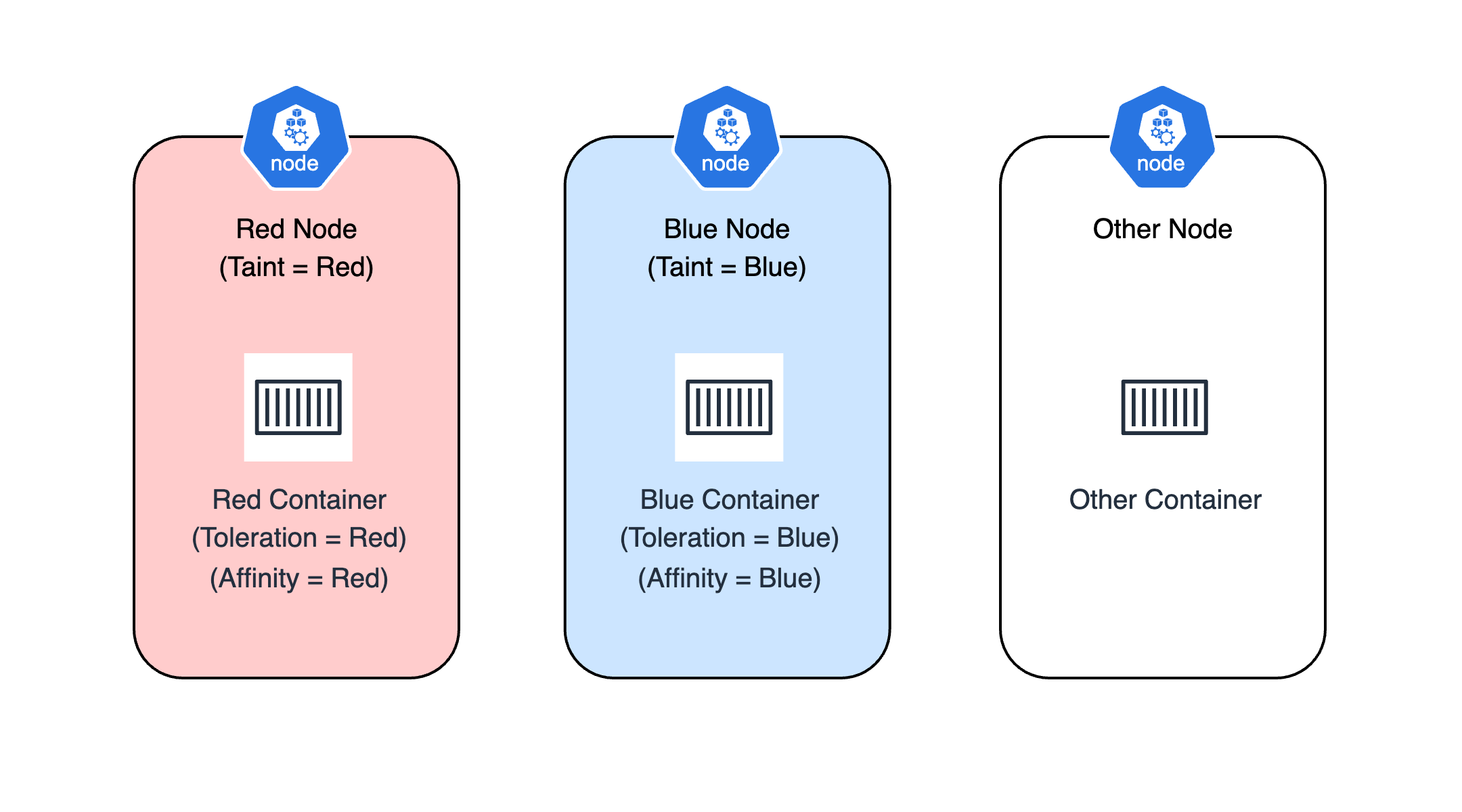 Taints and Tolerations 기능과 Node Affinity 를 적절히 조합하여 사용하면 원하는 Pod 를 원하는 Node 에 배치시키는 것을 보장할 수 있다. 위 그림처럼 Node 를 Taint 시켜 원하는 Pod 외의 Pod 가 배치되는 것을 막고, Node Affinity 를 통해 Pod 가 특정 Node 에 배치되게끔 설정할 수 있다.
Taints and Tolerations 기능과 Node Affinity 를 적절히 조합하여 사용하면 원하는 Pod 를 원하는 Node 에 배치시키는 것을 보장할 수 있다. 위 그림처럼 Node 를 Taint 시켜 원하는 Pod 외의 Pod 가 배치되는 것을 막고, Node Affinity 를 통해 Pod 가 특정 Node 에 배치되게끔 설정할 수 있다.
Resource Requirements and Limits
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"Pod 가 Node 에 배치되면 Node 의 리소스를 사용하게 되는데 위처럼 리소스 사용량을 지정해줄 수 있다. Request 와 Limit 은 말 그대로 Pod 가 필요한 최소 용량의 리소스와 최대로 점유할 수 있는 리소스를 의미한다. CPU 의 경우 Limit 을 절대 초과하지 않지만 메모리의 경우 어느정도 초과분을 사용할 수 있게 한다. 다만 너무 오랜 기간 Limit 을 초과하면 OOM 이 발생하며 Pod 가 제거될 수 있다.
LimitRange
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # 기본 Limit
cpu: 500m
defaultRequest: # 기본 Request
cpu: 500m
max: # 최대 Limit
cpu: "1"
min: # 최소 Request
cpu: 100m
type: ContainerK8s Cluster 에 배치될 모든 Pod 에 대한 기본값을 설정해주고 싶은 경우 LimitRange Object 를 활용할 수 있다. LimitRange 는 namespace 내에서 적용되며 메모리도 동일하게 적용 가능하다. LimitRange Object 가 생성된 이후 적용되기 때문에 중간에 수정한다 하더라도 기존에 생성되어 있는 Pod 엔 적용되지 않고 새로 생성하는 Pod 에만 적용된다. 범위를 설정해주는 것이기 때문에 requests.cpu: 700m 짜리 Pod 를 생성하려고 하면 범위 외 요청이기에 Pod 생성이 제한된다.
ResourceQuota
apiVersion: v1
kind: ResourceQuota
metadata:
name: my-resource-quota
spec:
hard:
requests.cpu: 4
requests.memory: 4Gi
limits.cpu: 10
limits.memory: 10Ginamespace 마다 리소스 사용량을 제한하고 싶을 경우 ResourceQuota 를 활용하여 namespace 전체에 리소스 요청 및 제한을 설정할 수 있다.
DaemonSets
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: monitoring-daemon
labels:
app: nginx
spec:
selector:
matchLabels:
app: monitoring-agent
template:
metadata:
labels:
app: monitoring-agent
spec:
containers:
- name: monitoring-agent
image: monitoring-agentDaemonSet 은 모든 Node 에 1개의 Pod 를 배치하고 싶을 때 사용할 수 있는 Object 이다. 예를 들어 Datadog-Agent 와 같은 모니터링 에이전트 Pod 를 DaemonSet 을 통해 각 노드에 1개씩 배치할 수 있다. kube-proxy 역시 DaemonSet 으로 배포되어 있는 컴포넌트다.
K8s 는 DaemonSet 을 모든 Node 에 배포하기 위해 NodeAffinity 와 Default Scheduler 를 사용한다.
kubectl create -f daemon-set-definition.yaml
kubectl get daemonsets
kubectl describe daemonsets monitoring-daemon
위와 같은 커맨드로 DaemonSet 을 생성하고 조회할 수 있다.
Static Pods
Static Pod 은 kube-api-server 나 kube-scheduler 가 아닌 kubelet 이 생성하고 관리하는 Pod 다. kubelet 은 Node 의 /etc/kubernetes/manifests 디렉터리에 정의된 yaml 파일을 주기적으로 확인하고 해당 Node 에서 실행되도록 보장한다. kubeadm 이 Master Node 를 구성할 때 Static Pod 형식으로 controller-manager, kube-api-server, etcd 등을 생성한다. 때문에 kubectl get pods -n kube-system 으로 Pod 를 조회했을 때 Master Node 의 컴포넌트들이 Pod 로 실행되고 있는 것을 확인할 수 있는 것이다.
Priority Classes
root@controlplane ~ ✖ k get priorityclasses
NAME VALUE GLOBAL-DEFAULT AGE PREEMPTIONPOLICY
system-cluster-critical 2000000000 false 24m PreemptLowerPriority
system-node-critical 2000001000 false 24m PreemptLowerPriorityapiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
description: "This priority class should be used for XYZ service pods only."
globalDefault: false
preemptionPolicy: PreemptLowerPriority
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 8080
priorityClassName: high-priorityPod 의 우선순위를 정해주는 방법이다. k8s components 와 같이 System 에 중요한 Pod 일 경우 2,000,000,000 ~ 1,000,000,000 범위를 할당하고 그 외 Pod 는 1,000,000,000 ~ -2,147,483,648 범위 내에서 우선순위를 할당할 수 있다. default Priority Value 는 0 이다.
k8s cluster 에 리소스가 부족한 경우 preemptionPolicy default 설정인 PreemptLowerPriority 로 인해 낮은 priority 를 가진 Pod 이 제거되고 그 자리를 차지하게 된다. 이를 방지하기 위해 never 옵션을 줄 수도 있다.
Multiple Schedulers
apiVersion: v1
kind: Pod
metadata:
name: my-custom-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --config=/etc/kubernetes/my-scheduler-config.yaml
image: k8s.gcr.io/kube-scheduler-amd64:v1.11.3
name: kube-schedulerapiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: true
resourceNamespace: kube-system
resourceName: lock-object-my-schedulerK8s 는 Default Scheduler 외에도 여러개의 Scheduler 를 사용할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
schedulerName: my-custom-scheduler특정 Scheduler 를 사용하여 Pod 를 배포하고 싶을 경우 spec.schedulerName 에 Scheduler 이름을 지정해주면 된다.
kubectl get events
위 명령어를 통해 어떤 Scheduler 가 Pod 를 배포했는지 확인도 가능하다.
Configuring Scheduler Profiles
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler-1
plugins:
score:
disabled:
- name: TaintToleration
enabled:
- name: MyCustomPluginA
- name: MyCustomPluginB
- schedulerName: my-scheduler-2
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
- schedulerName: my-scheduler-3Scheduler 는 Scheduling Queue → Filtering → Scoring → Binding 순으로 Pod 가 배포될 적절한 Node 를 선정해낸다.
- Scheduling Queue: Pod definition file 에 지정된 우선순위를 기준으로 생성할 Pod 를 정렬한다.
- Filtering: NodeName, NodeUnschedulable, TaintToleration, NodeAffinity 등을 기준으로 Pod 가 배치될 수 있는 Node 를 골라낸다.
- Scoring: 필터링된 Node 들 중 Pod 가 배치된 후 남은 리소스 등 여러가지 사항들을 고려하여 Node 를 선택한다.
- Binding: 선택된 Node 에 Pod 를 배치한다.
Admission Controllers
kubectl 로 kube-api-server 에 명령어를 보내면 Authentication 과 Authorization 을 거쳐 명령어를 실행하게 된다. Authorization 에서 RBAC 을 통해 Role 을 기반으로 K8s Object 를 조작하는 명령을 제한할 수 있는데 더 복잡한 제어가 필요한 경우 Admission Controller 를 통해 제어할 수 있다.
kubectl exec -it kube-apiserver-controlplane -n kube-system -- kube-apiserver -h | grep enable-admission-plugins
위 명령어를 실행해보면 어떤 플러그인들이 활성화되어 있는지 확인할 수 있다.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
- --authorization-mode=Node,RBAC
- --advertise-address=172.17.0.107
- --allow-privileged=true
- --enable-bootstrap-token-auth=true
- --enable-admission-plugins=NodeRestriction,NamespaceAutoProvision
image: k8s.gcr.io/kube-apiserver-amd64:v1.11.3
name: kube-apiserver특정 플러그인을 활성화하고 싶을 경우 enable-admission-plugins 옵션을 통해 활성화 할 수 있다.
Validating and Mutating Admission Controllers
Admission Controller 들은 크게 Mutating Controller 와 Validating Controller 로 나뉜다. 예를 들어 어떤 Object 에 지정한 Namespace 가 존재하지 않을 때 NamespaceAutoProvision 이 다른 Namespace 를 지정하고 NamespaceExists 가 Namespace 존재 여부를 확인한다.