Switching Routing
ip link
서로 다른 Host 가 통신하기 위해선 두 Host 를 이어주는 Switch 가 필요하다. Host 를 Switch 에 연결하려면 Network Interface 가 필요한데, 위 명령어를 통해 Host 의 Network Interface 를 확인할 수 있다. Linux 의 경우 eth0 라는 Network Interface 를 확인할 수 있다.
ip addr
ip addr add 192.168.1.10/24 dev eth0
Host 들이 Switch 에 연결된 이후 위 명령어를 통해 Host 에 IP 주소를 할당해줄 수 있다.
ip route
ip route add 192.168.2.0/24 via 192.168.1.1
ip route add default via 192.168.2.1
ip route add 0.0.0.0 via 192.168.2.1
서로 다른 Switch 가 통신하기 위해선 두 Switch 를 이어주는 Router 가 필요하다. 192.168.2.0/24 의 주소를 가지는 Switch 에 접근하기 위해선 Router 의 192.168.1.1 주소를 거쳐가면 된다는 의미다. default 또는 0.0.0.0 는 이외 모든 주소를 의미하며 즉, 인터넷에 접근하기 위해선 192.168.2.1 주소를 거쳐가야 된다는 의미다.
cat /proc/sys/net/ipv4/ip_forward
echo 1 > /proc/sys/net/ipv4/ip_forward
Router 가 192.168.1.1 와 192.168.2.1 의 주소를 가지고 있다는 것은 eth0 과 eth1 이 할당됐다는 의미이고, 기본적으로 서로 다른 Network Interface 간에 Packet 전달은 막혀있다. 위 명령어를 통해 ip_forward 값을 1 로 바꿔주면 Router 내부에서 Packet 를 Network Interface 간에 전달할 수 있도록 해줄 수 있다. 재부팅할 경우 설정값이 초기화 되기 때문에 /etc/sysctl.conf 에서 net.ipv4.ip_forward 값을 1 로 설정해주면 영구적으로 설정할 수도 있다.
DNS
cat /etc/hosts
IP 주소 대신 Name 으로 Host 를 식별하기 위해 위 경로에 IP 주소에 해당하는 Host Name 을 지정해 줄 수 있다. 대신 모든 Host 에 필요하기 때문에 관리하기가 어려워진다. 때문에 DNS 서버를 활용해 하나의 관리포인트로 통합한다.
cat /etc/resolv.conf
DNS 서버의 주소는 위 경로에 저장하여 사용할 수 있다. 8.8.8.8 은 Google 이 제공하는 DNS 서버다.
cat /etc/nsswitch.conf
...
hosts: files dns
...
기본적으로 /etc/hosts 에서 주소를 찾고 없으면 /etc/resolv.conf 에서 주소를 찾는데, 위 설정파일에서 순서를 변경할 수도 있다.
CoreDNS
wget https://github.com/coredns/coredns/releases/download/v1.7.0/coredns_1.7.0_linux_amd64.tgz
cat > /etc/hosts
192.168.1.10 web
192.168.1.11 db
192.168.1.15 web-1
192.168.1.16 db-1
192.168.1.21 web-2
192.168.1.22 db-2
DNS 서버를 구축하려면 DNS 소프트웨어가 설치된 Host 가 필요하다. CoreDNS 라는 DNS 소프트웨어를 설치하여 DNS 서버를 구축할 수 있다.
Network Namespaces
ip netns add red
ip netns add blue
Container 가 namespace 를 통해 프로세스를 격리하듯 Network 역시 격리할 수 있다. 위 명령어는 red 와 blue 라는 이름을 가진 Network Namespace 를 생성한다는 의미다.
ip netns exec red ip link
ip -n red link
ip link 명령어를 통해 Network Interface 를 확인했듯 Network Namespace 의 Network Interface 를 확인하기 위해선 위 명령어를 사용할 수 있다.
ip -n red arp
ip -n red route
arp 와 route 역시 동일한 방법으로 확인할 수 있다.
Virtual Cable
ip link add veth-red type veth peer name veth-blue
위 명령어로 가상 케이블을 생성하고,
ip link set veth-red netns red
ip link set veth-blue netns blue
ip -n red addr add 192.168.15.1/24 dev veth-red
ip -n blue addr add 192.168.15.2/24 dev veth-blue
ip -n red link set veth-red up
ip -n blue link set veth-blue up
위 명령어로 Network Namespace 끼리 연결해줄 수 있다.
Linux Bridge
ip link add v-net-0 type bridge
ip link set dev v-net-0 up
Network Namespace 가 많아질 경우 Switch 역할을 하는 Linux Bridge 를 활용할 수 있다.
ip link add veth-red type veth peer name veth-red-br
ip link set veth-red netns red
ip link set veth-red-br master v-net-0
ip -n red addr add 192.168.15.1 dev veth-red
ip -n red link set veth-red up
이후 Network Namespace 와 Bridge 를 연결하기 위한 Virtual Cable 을 생성 및 할당해주고, IP 주소 도 할당해 준 뒤 활성화 해주자.
ip addr add 192.168.15.5/24 dev v-net-0
위 명령어를 통해 Host 와 Bridge 를 연결해주자.
ip netns exec blue ip route add 192.168.1.0/24 via 192.168.15.5
Namespace 가 외부 Host 와 통신하기 위해선 외부에 192.168.1.0/24 의 주소를 가지는 Switch 와 routing 설정을 해줘야한다. 위 명령어를 사용하면 192.168.15.5 의 주소를 가지는 v-net-0 을 통해 호스트의 eth0 를 거쳐 외부로 향하게 된다.
iptables -t nat -A PREROUTING --dport 80 --to-destination 192.168.15.2:80 -j DNAT
외부 Host 가 다른 Host 의 Network Namespace 에 접근하기 위해선 위 명령어로 포트포워딩 해줘야 한다.
Docker Networking
ip link
08. Docker Networking 에서 배운 bridge 가 바로 Linux Bridge 다. ip link 로 확인해보면 docker0 라는 이름을 가진 Network Interface 를 확인할 수 있다.
ip netns
Docker Container 를 실행하면 Network Namespace 도 마찬가지로 자동으로 생성된다.
iptables -nvL -t nat
포트포워딩도 마찬가지. Docker Container 를 실행할 때 iptable 설정까지 자동으로 생성된다.
즉, Docker Container 를 생성할 때, 네트워크 측면에선 내부적으론 위에서 언급한 모든 작업들이 자동으로 수행되던 것이다…
CNI
ls /opt/cni/bin/
CNI 를 기준으로 Networking 기능을 구현하여 기본적인 동작과 플러그인등을 활용할 수 있다. Docker 의 경우 따로 CNM 이라는 기준으로 CNI 를 따르지 않기 때문에 K8s 는 Docker Container 를 None 으로 생성한 뒤 직접 Bridge 에 할당하는 작업을 따로 수행한다.
Cluster Networking
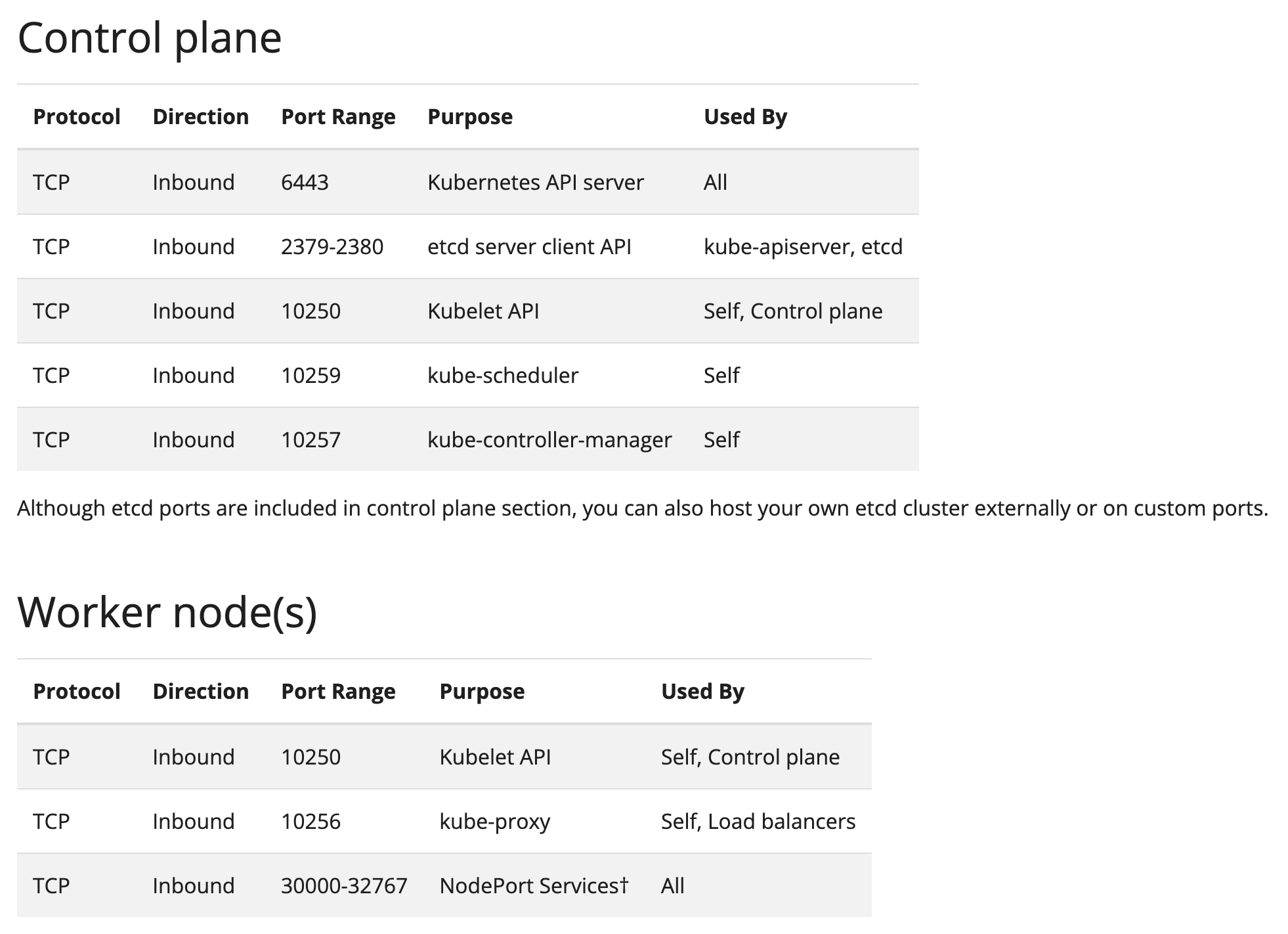 K8s 도 결국 Master 와 Worker Node 간의 통신이 가능해야 함으로 각 Component 마다 위와 같은 Port 들을 열어줘야 한다. 자세한 내용은 공식 문서를 참고하자.
K8s 도 결국 Master 와 Worker Node 간의 통신이 가능해야 함으로 각 Component 마다 위와 같은 Port 들을 열어줘야 한다. 자세한 내용은 공식 문서를 참고하자.
Pod Networking
서로 다른 Node 에 위치한 Pod 간 통신을 활성화 하기 위해선 아래와 같은 작업이 필요하다.
ip link add v-net-0 type bridge
ip link set dev v-net-0 up
ip addr add 10.244.1.1/24 dev v-net-0
먼저 각 Node 마다 Bridge 를 생성해준 뒤,
ip route add 10.244.2.2 via 192.168.1.12
다른 Node 의 Bridge 로 향하는 Route 를 설정해준다. 혹은 라우터를 활용해 Routing 설정을 한 곳에서 관리하는 방법도 있겠다.
Container 가 생성될 때 마다 Node 에 하나하나 접속해서 위 명령어들을 실행해야한다. Node 가 많아지고 네트워킹이 복잡해지면 해당 작업이 번거로워지기 때문에 자동화된 스크립트를 활용할 수 있다.
# net-script.sh
ADD)
# Create veth pair
# Attach veth pair
# Assign IP Address
# Bring Up Interface
DEL)
# Delete veth pair위와 같은 기준으로 작성된 스크립트를 활용해 Container 가 생성될 때 마다 실행해주면 Pod 간 네트워킹을 자동화할 수 있다. 위 기준을 CNI 가 제공하고 다양한 CNI Plugin 들이 구현된 스크립트를 제공한다.
CNI in K8s
K8s 는 기본적으로 Pod 간의 통신을 지원하지 않는다. 때문에 Pod 간 통신이 가능하도록 하려면 CNI Plugin 을 추가적으로 설치해 사용해야한다.
ExecStart=/usr/local/bin/kubelet \
...
--network-plugin=cni \
--cni-bin-dir=/opt/cni/bin \
--cni-conf-dir=/etc/cni/net.d \
...
CNI 를 설정해주기 위해선 kubelet 을 실행할 때 옵션으로 넘겨주면된다.
ls /opt/cni/bin
위 경로에서 사용할 수 있는 모든 CNI Plugin 들을 확인할 수 있다.
ls /etc/cni/net.d
위 경로에 존재하는 파일을 바탕으로 CNI Plugin 를 설정할 수 있다.
cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
CNI weave
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
Weave 는 CNI Plugin 중 하나인 솔루션으로 위와 같이 Pod 로 생성해서 운영할 수 있다.
IP Address Management - Weave
cat /etc/cni/net.d/net-script.conflist
{
"cniVersion": "0.2.0",
"name": "mynet",
"type": "net-script",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.244.0.0/16",
"routes": [
{
"dst": "0.0.0.0/0"
}
]
}
}
Pod 간 할당되는 IP 를 관리하기 위해 CNI 에선 DHCP 와 host-local 이라는 빌트인 플러그인을 제공한다. 해당 설정 역시 위 파일에서 관리할 수 있다.
Service Networking
K8s 에선 Pod 끼리 통신하는 대신 Service Object 를 통해 Cluster 내 Pod 간의 통신 또는 외부와의 통신을 제공한다. Pod 이 namespace 등을 할당 받아 실제로 존재하는 것과 달리, Service 는 kube-proxy 에 의해Cluster 에 걸쳐 Forwarding Rule 을 가지고 생성되는 Virtual Object 다.
kube-proxy --proxy-mode [ userspace | iptables | ipvs ]
kube-proxy 를 실행할 때 proxy-mode 옵션을 통해 Forwarding Rule 을 관리할 버전을 설정할 수 있다.
kube-api-server --service-cluster-ip-range ipNet (Default: 10.0.0.0/24)
kube-api-server 를 실행할 때 Service 가 가질 수 있는 IP range 를 지정해줄 수 있다. Service IP range 와 Pod IP range 는 겹치면 안된다는 것도 참고하자.
iptables -L -t nat | grep db-service
iptables 모드로 생성한 Service 의 Forwarding Rule 을 위 명령어를 통해 확인할 수 있다.
DNS in K8s
<POD-IP-ADDRESS>.<namespace-name>.pod.cluster.local
<service-name>.<namespace-name>.svc.cluster.local
K8s 에서 Pod 과 Service 는 위 규칙에 따라 Domain Name 을 할당 받는다.
CoreDNS in K8s
Pod 과 Service 들이 서로 Domain Name 으로 통신하기 위해 DNS 를 활용하는데, K8s 에선 CoreDNS 솔루션을 기반으로 한다. 기본적으로 Deployment 형태로 배포되며 Service 역시 제공해 Pod 과 Service 들이 kube-dns Service 를 향해 nslookup 을 수행할 수 있다.
kubectl get configmap -n kube-system
kubectl describe cm -n kube-system
CoreDNS 의 설정은 ConfigMap 으로 구성 가능하다.
cat /var/lib/kubelet/config.yaml | grep -A2 clusterDNS
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
CoreDNS 는 kubelet 으로 부터 배포되기에 kubelet 의 설정파일에서 CoreDNS 의 IP 를 확인할 수 있다.
kubectl run -it --rm --restart=Never test-pod --image=busybox -- cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
pod "test-pod" deleted
Pod 내부에 있는 resolv.conf 파일에서 CoreDNS IP 가 적용되어 있는 것을 확인할 수 있다.
Ingress
Ingress 는 다양한 Service 로의 트래픽을 구분하고 도메인 또는 경로별로 라우팅하는 일종의 Load Balancer 역할을 한다. Ingress 는 Ingress Controller 와 Ingress Resoucres 로 구성된다. Ingress Controller 는 실제로 트래픽을 처리하는 구현체로 Nginx, HAProxy, ALB 등이 구현체로 사용된다.
Ingress Controller
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-controller
spec:
replicas: 1
selector:
matchLabels:
name: nginx-ingress
template:
metadata:
labels:
name: nginx-ingress
spec:
serviceAccountName: ingress-serviceaccount
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.21.0
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443apiVersion: v1
kind: Service
metadata:
name: ingress
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
- port: 443
targetPort: 443
protocol: TCP
name: https
selector:
name: nginx-ingressGCP Load Balancer, Nginx, Istio 등이 이에 해당하며 Deployment, Service, ConfigMap, Auth 등 다양한 K8s Object 로 구성된다.
Ingress Resource
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-wear-watch
spec:
rules:
- host: wear.my-online-store.com
http:
paths:
- backend:
serviceName: wear-service
servicePort: 80
- host: watch.my-online-store.com
http:
paths:
- backend:
serviceName: watch-service
servicePort: 80트래픽 라우팅 룰을 설정하는 곳으로 Ingress Object 가 여기서 사용된다.
Service vs Ingress
Kubernetes 에서 Pod 는 동적으로 생성되고 사라지기에 IP 역시 자주 바뀐다. 때문에 외부 또는 클러스터 내에서 특정 Pod 에 안정적으로 접근하려면 고정된 네트워크 접근 방법이 필요하다. 이를 해결하기 위해 사용되는 것이 Service 이고 외부 HTTP/HTTPS 트래픽을 세밀하게 제어하기 위해 Ingress 가 사용된다. 즉, Service 는 내부/외부 통신을 연결하는 기본 통로, Ingress 는 HTTP/HTTPS 트래픽을 라우팅하는 고급 제어 도구다. Service 는 4계층(L4, TCP/UDP), Ingress 는 7계층(L7, HTTP/HTTPS)를 담당한다.
| Service | Ingress | |
|---|---|---|
| 목적 | Pod 들을 묶어 네트워크 접근 지점 제공 | HTTP/HTTPS 요청을 경로 기반으로 라우팅 |
| 계층 | L4, TCP/UDP | L7, HTTP/HTTPS |
| 외부 노출 | 필요 시 NodePort, LoadBalancer | 도메인/경로 기반 트래픽 제어 |
| 복잡도 | 단순 연결 | 라우팅, 인증, TLS 등 고급 제어 |
| 연관관계 | Ingress 는 내부적으로 Service 를 사용 | Service 없이는 Ingress 도 작동하지 않음 |
| Service 는 여러 Pod 를 하나의 IP 로 접근 가능하게 해주는 기본 네트워크 객체이고, Ingress 는 HTTP 요청을 다양한 경로와 도메인으로 라우팅하는 고급 컨트롤러다. 즉, Ingress 는 Service 를 대체하는 것이 아닌 확장하는 상위 개념이다. Service 가 있어야 Ingress 가 트래픽을 어디로 보낼지 결정할 수 있다. 실무에선 Service + Ingress 조합으로 외부 트래픽을 내부 Pod 로 보낸다. |
Gateway API
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: nginx
spec:
controllerName: nginx.org/gateway-controller
--- # TLS/로드밸런서(IP, 인증서)는 운영자가 Gateway 에만 정의
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: example-gateway
spec:
gatewayClassName: nginx
listeners:
- name: https
protocol: HTTPS
port: 443
tls:
mode: Terminate
certificateRefs:
- kind: Secret
name: tls-secret
allowedRoutes:
namespaces:
from: All
--- # 개발자는 자기 Route 리소스만 관리 (서비스 라우팅)
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: app-route
spec:
parentRefs:
- name: example-gateway
hostnames:
- "www.example.com"
rules:
- matches:
- path:
type: PathPrefix
value: /login
backendRefs:
- name: example-svc
port: 8080Ingress 의 경우 Ingress Controller 가 Nginx 인지, Traefik 인지에 따라 annotation 에서 해주는 설정이 달라질 수 있다. Ingress 는 기본적으로 HTTP/HTTPS 정도만 처리하기에 gRPC, TCP, UDP 같은 프로토콜을 지원하기 위해선 Ingress Controller 에 맞는 annotation 을 붙여 사용해야 한다. 즉, 표준이 아닌 Ingress Controller 별 종속적인 기능에 의존성이 생기는 문제가 있다.
또, Ingress 는 운영팀(인프라) 개발팀(앱) 보안팀(정책)이 역할을 나눠 가질 수 없는 구조로 이루어져 있다. 트래픽 라우팅, TLS, 도메인, 리다이렉트 등 모든 설정이 하나의 Ingress 리소스 안에 섞여버리는 문제가 있다.
K8s 에선 이를 해결하기 위해 Gateway API 라는 프로젝트를 시작했고, 제공되는 GatewayClass(인프라팀), Gateway(운영자), HTTPRoute(개발자) 등 역할이 분리된 새로운 Object 를 통해 Controller 에 종속되지 않는 설정과 리소스 관리 충돌을 방지할 수 있다.
CoreDNS vs ExternalDNS
CoreDNS 는 클러스터 내부의 DNS 질의를 처리하는 내부 DNS 서버이다. ExternalDNS 는 Ingress 나 Service 정보를 외부 DNS 제공자의 레코드를 자동으로 생성 및 동기화하는 컨트롤러이다.
CoreDNS
<service-name>.<namespace-name>.svc.cluster.local 등 클러스터 도메인에 DNS 질의를 담당한다. kube-system namespace 에 Deployment 와 관련 ConfigMap 으로 동작한다.
CoreDNS 의 질의 흐름은 아래와 같다.
- Pod 가 Service domain 으로 질의
- Pod 의
/etc/resolv.conf가 CoreDNS ClusterIP 를 name server 로 가리킴 - CoreDNS 의 kubernetes 플로그인이 Service endpoint 를 조회해 응답
- Cluster domain 이 아니면 forward 플러그인이 upstream 으로 포워딩
ExternalDNS
Ingress, Service, Gateway 등 리소스를 감시해 R53, Cloud DNS 등 외부 DNS 제공자에 A, AAAA, CNAME 등의 레코드를 생성한다. 즉, 외부인터넷에서 kubernetes cluster 로 접근할 때 필요한 domain name 들을 외부 DNS 와 연동해주는 역할을 한다.
ExternalDNS 의 동기화 흐름은 아래와 같다.
- 컨트롤러가 Ingress, Service, Gateway 등 리소스를 감시
- 호스트명 또는 주석을 읽어 목표 레코드를 계산
- 소유권을 관리하는 TXT 레코드 확인
- DNS 제공자 API 로 A, AAAA, CNAME 등을 생성 및 갱신